
在前面开发一个社区团购微信接龙报表自动生成的Excel插件这篇文章中,介绍了如何开发一个根据买菜供货菜单结合群接龙自动生成统计报表的Excel插件。在那篇文章里,是手动输入购物清单里的商品和价格的,其主要原因是上头给的就是图片,而不是Excel文件。另外,我们在工作中通常会遇到这种情况,领导给的就是一个图片,比如Excel文件的截图,但是我们需要把图片里的文字或者数字给提取出来,当然,如果脸皮够厚,可以直接要原始文件,但作为一个卑微的码农,通常是不敢麻烦领导的,只能要么默默地手动输入,要么996一下研究怎么自动化实现。
从图片提取文字,这是一个比较常见的功能,它需要一个叫OCR (Optical Character Recognition),光学字符识别的功能。一些带有拍照识图,拍照翻译,拍照识别花花草草的应用,都是OCR应用的场景。
经过一番996,我这里实现了通过OCR识别出图片里的文字和表格,而且精度极高(当然这是站在巨人的肩膀上),这里简单介绍一下。
需求
前面一篇文章说过,要根据菜单和价格,以及微信接龙数据生成报表,首先需要把菜单和价格输入到表格里。
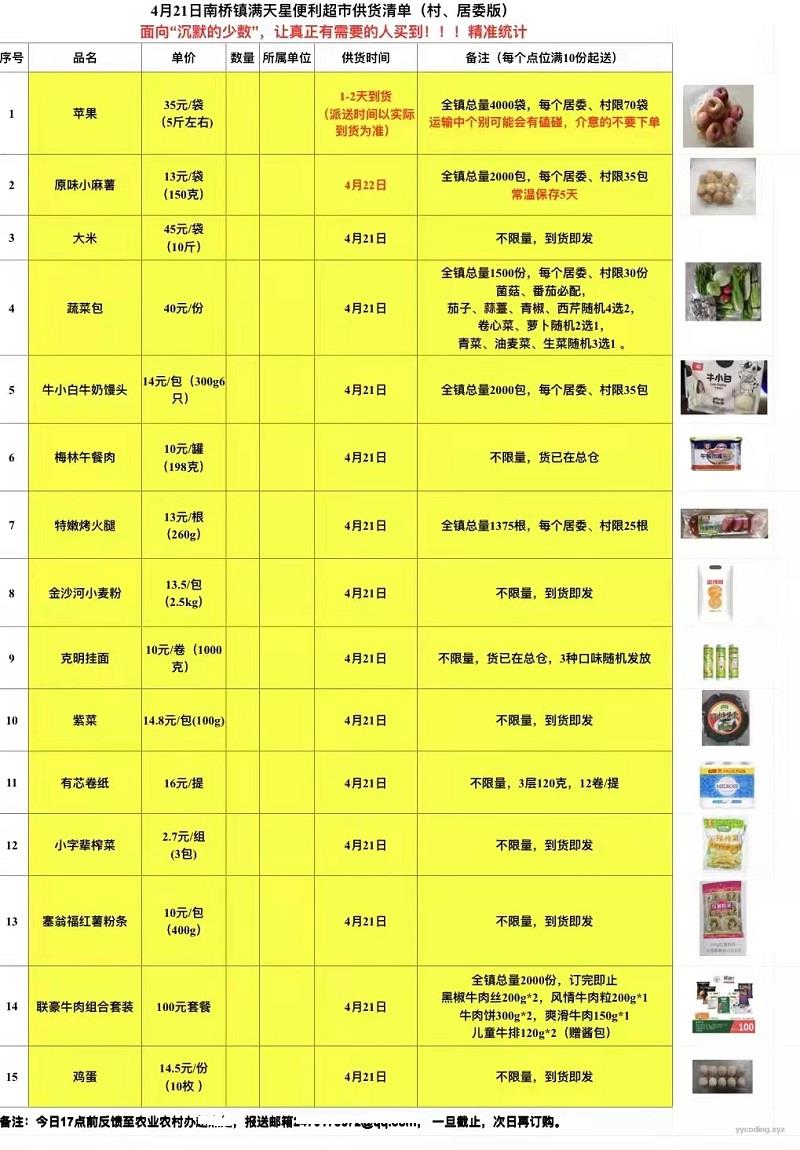
▲4月21日满天星供货清单
需要把第一列和第二列,录入到Excel里,如下。
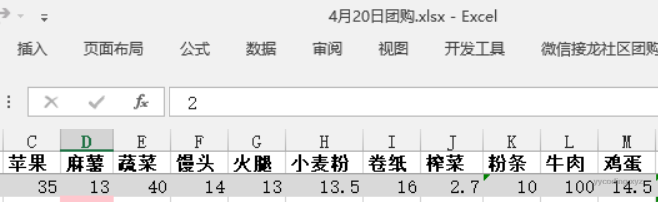
▲根据供货单,手工录入的菜单和价格信息
上图是根据供货图片,手工录入的商品和价格信息,非常的不友好,假设如果商品数量足够多,眼睛和手会感觉很累。
先看疗效
我这里使用OCR,自动识别出图片里的文字,然后稍作整理,就能获得上述的菜单和价格,如下(.gif动画文件已经经过压缩,但仍有些大):
 ▲在Excel里面添加OCR功能
▲在Excel里面添加OCR功能
如上图,在之前的插件里面,添加了一个OCR功能,首先选择插入待识别的图片,也可以直接在Excel里面插入图片。插入完成之后,需要选中该图片,然后点击识别图片,就能把图片里面的表格内容插入到单元格里面,默认的是当前sheet页的第一个单元格。
因为图片里商品名称和价格是竖排的,所以复制完,粘贴的时候,选择“转置”就可以得到报表中需要的格式,然后做一些微调就能够使用。可以看到,这里的识别效果相当精确。
代码实现
Excel插件相关的开发可以参考上一篇文章,这里主要讲解OCR识别的实现。OCR属于计算机视觉范畴,在这方面比较有名的库就是OpenCV了,在.NET方面,对它的包装有Emgu.CV和OpenCVSharp4,前者存在的时间相当久远,后者是新兴的类库,是一个日本人开发的,它俩都在Github上开源,但遵守的开源协议不一样,后者更宽松一些。另外语法方面后者也对.NET比较友好,Emgu有些繁琐,所以OpenCVSharp4大有赶超Emgu之势。这里我用的是OpenCVSharp4库。
谈到OCR识别,我最早无意中看到了这篇文章 我做的百度飞桨PaddleOCR .NET调用库,这位作者早先在.net conf 2021技术峰会 上做过一个《.NET玩转计算机视觉OpenCV》的演讲(该视频的07:00~35:00),看完之后收获很多,我在这里的实现大部分参考了该作者演讲里提到的内容。
计算机图形处理在.NET里面使用的是OpenCVSharp4,OCR识别这里用的是百度的PaddleOCR,上文作者对该类库进行了.NET封装。所以在应用程序中,需要引用这些nuget包。
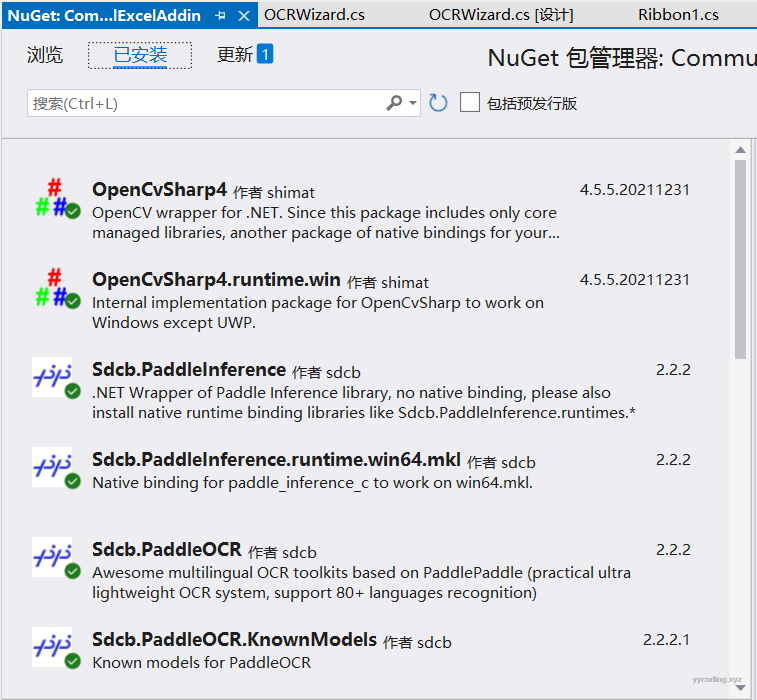 ▲OCR识别用到的nuget包,前面两个是OpenCV的.NET包装,后面两个是PaddleOCR的.NET包装
▲OCR识别用到的nuget包,前面两个是OpenCV的.NET包装,后面两个是PaddleOCR的.NET包装
因为VSTO Excel的一些接口不讲武德:一些对象是动态类型,Visual Studio无法提供智能提示,一些方法他会以抛出异常的方式来表示用户“没有选择”、“为空”、“不存在”,相当变态(比如InputBox、RangeSelection,Style如果用户没有进行选择或不存在(它又没提供判断是否存在的方法),那么就会直接抛出异常)。所以我这里为了实现OCR,先用WPF来做demo,然后再往Excel插件上移植。
WPF里的OCR实现
界面非常简单,最上面三个按钮,左边原始图片,右边识别结果。xaml文件如下:
<Window x:Class="OCR.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:OCR"
mc:Ignorable="d"
Title="MainWindow" Height="600" Width="1024">
<Grid>
<Grid.RowDefinitions>
<RowDefinition Height="20"/>
<RowDefinition Height="*"/>
</Grid.RowDefinitions>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="3*"/>
<ColumnDefinition Width="*"/>
</Grid.ColumnDefinitions>
<StackPanel Orientation="Horizontal">
<Button x:Name="btnOpen" Click="btnOpen_Click" Margin="10 0 0 0">打开</Button>
<Button x:Name="btnRecognize" Click="btnRec_Click" Margin="10 0 0 0">识别文字</Button>
<Button x:Name="btnRecognizeTable" Click="btnRecTable_Click" Margin="10 0 0 0">识别表格</Button>
</StackPanel>
<ScrollViewer Grid.Row="1" Grid.Column="0" HorizontalScrollBarVisibility="Visible"
VerticalScrollBarVisibility="Visible">
<Canvas ScrollViewer.CanContentScroll="True" Width="1000" Height="600" >
<Image x:Name="image"/>
<Path x:Name="recognizeObject" Stretch="None" Stroke="Red" StrokeThickness="1"/>
</Canvas>
</ScrollViewer>
<ScrollViewer Grid.Row="1" Grid.Column="1">
<ListBox x:Name="resultLst"/>
</ScrollViewer>
</Grid>
</Window>我这里UI界面没有做任何美化,当点击“打开”按钮时,将图片显示出来并保存图片的位置地址:
private string imageUrl;
private void btnOpen_Click(object sender, RoutedEventArgs e)
{
OpenFileDialog dlg = new OpenFileDialog();
dlg.Filter = "JPG Files (*.jpg,*.jpeg)|*.jpg;*.jpeg|PNG Files (*.png)|*.png|GIF Files (*.gif)|*.gif))";
if ((bool)dlg.ShowDialog())
{
bimage = new BitmapImage(new Uri(dlg.FileName));
image.Source = bimage;
imageUrl = dlg.FileName;
}
}第二个按钮“识别文字”,当点击后,会调用OCR来识别图片中的文字。代码如下:
private async void btnRec_Click(object sender, RoutedEventArgs e)
{
OCRModel _chs = KnownOCRModel.PPOcrV2;
await _chs.EnsureAll();
using (PaddleOcrAll all = new PaddleOcrAll(_chs.RootDirectory, _chs.KeyPath)
{
AllowRotateDetection = true, /* 允许识别有角度的文字 */
Enable180Classification = false, /* 允许识别旋转角度大于90度的文字 */
})
{
// Load local file by following code:
//
List<PaddleOcrResultRegion> recRegion = new List<PaddleOcrResultRegion>();
using (Mat src2 = Cv2.ImRead(imageUrl))
{
PaddleOcrResult result = all.Run(src2);
Debug.WriteLine("Detected all texts: \n" + result.Text);
recRegion = result.Regions.ToList();
}
var boxes = new GeometryGroup();
foreach (PaddleOcrResultRegion region in recRegion)
{
Debug.WriteLine(region);
double leftX, topY, width = 0, height = 0;
double centerX = region.Rect.Center.X;
double centerY = region.Rect.Center.Y;
width = region.Rect.Size.Width;
height = region.Rect.Size.Height;
leftX = centerX - width / 2;
topY = centerY - height / 2;
Transform rotateTransform = new RotateTransform(region.Rect.Angle, centerX, centerY);
boxes.Children.Add(new RectangleGeometry(new System.Windows.Rect(leftX, topY, width, height), 0, 0, rotateTransform));
string s = $"Text: {region.Text}, Score: {region.Score}, RectCenter: {region.Rect.Center}, RectSize: {region.Rect.Size}, Angle: {region.Rect.Angle}";
FormattedText text = new FormattedText(region.Text, CultureInfo.CurrentCulture, FlowDirection.LeftToRight, new Typeface("宋体 Bold"), 12, Brushes.Black, VisualTreeHelper.GetDpi(this).PixelsPerDip);
Geometry geometry = text.BuildGeometry(new System.Windows.Point(centerX - text.Width / 2, centerY));
//geometry.Transform = rotateTransform;
boxes.Children.Add(geometry);
resultLst.Items.Add(s);
}
recognizeObject.Data = boxes;
}
}首先要初始化OCR识别模型,这里使用的PPOCRV2这个模型,他可以识别中英文,如果要专门识别英文,可以选择其他模型。
OCRModel _chs = KnownOCRModel.PPOcrV2;
await _chs.EnsureAll();实例化之后,调用EnsureAll方法,他会下载相关的模型文件和数据到本地。紧接着初始化PaddleOCR,这里用到了前面选择的模型设置,并且这里设置了一些识别参数,比如是否允许识别有角度的文字,是否允许识别旋转角度大于90度的数字等等:
using (PaddleOcrAll all = new PaddleOcrAll(_chs.RootDirectory, _chs.KeyPath)
{
AllowRotateDetection = true, /* 允许识别有角度的文字 */
Enable180Classification = false, /* 允许识别旋转角度大于90度的文字 */
})完成之后,需要把图片加载到OpenCV里来,转换为Mat格式,OpenCV直接提供了imRead方法,可以直接将文件路径名称传进去。
Mat src2 = Cv2.ImRead(imageUrl)当然它也提供了二进制数组的读取方法,比如加入要从网上下载一幅图片并加载到OpenCV里,可以使用另外的方法:
byte[] sampleImageData;
string sampleImageUrl = @"https://www.tp-link.com.cn/content/images/detail/2164/TL-XDR5450易展Turbo版-3840px_03.jpg";
using (HttpClient http = new HttpClient())
{
sampleImageData = await http.GetByteArrayAsync(sampleImageUrl);
}
using (OpenCvSharp.Mat src = OpenCvSharp.Cv2.ImDecode(sampleImageData, OpenCvSharp.ImreadModes.Color))
或者可以使用方法将BitmapImage转为二进制数组,然后共OpenCV调用:
public static byte[] BitmapImageToByteArray(BitmapImage bitmapImage)
{
byte[] data;
JpegBitmapEncoder encoder = new JpegBitmapEncoder();
encoder.Frames.Add(BitmapFrame.Create(bitmapImage));
using (MemoryStream ms = new MemoryStream())
{
encoder.Save(ms);
data = ms.ToArray();
}
return data;
}这里我们还是直接使用传入图片文件地址的形式,在读取到待处理的图片到Mat里面之后,然后调用OCR的Run方法就可以进行识别了。
PaddleOcrResult result = all.Run(src2);返回的PaddleOcrResult对象里,有Region列表,他里面存放有图片里所有的识别出来的文字区域、置信度、文字内容等信息,接下来需要在界面上把这些识别结果绘制到图片上。
在WPF中,在图片上绘制内容最讨巧的方式是,把图片跟Path对象放在一个Canvas里,并把Path放在图片的上方,然后直接在Path上绘制内容即可。
List<PaddleOcrResultRegion> recRegion = new List<PaddleOcrResultRegion>();
using (Mat src2 = Cv2.ImRead(imageUrl))
{
PaddleOcrResult result = all.Run(src2);
Debug.WriteLine("Detected all texts: \n" + result.Text);
recRegion = result.Regions.ToList();
}
var boxes = new GeometryGroup();
foreach (PaddleOcrResultRegion region in recRegion)
{
double leftX, topY, width = 0, height = 0;
double centerX = region.Rect.Center.X;
double centerY = region.Rect.Center.Y;
width = region.Rect.Size.Width;
height = region.Rect.Size.Height;
leftX = centerX - width / 2;
topY = centerY - height / 2;
Transform rotateTransform = new RotateTransform(region.Rect.Angle, centerX, centerY);
boxes.Children.Add(new RectangleGeometry(new System.Windows.Rect(leftX, topY, width, height), 0, 0, rotateTransform));
string s = $"Text: {region.Text}, Score: {region.Score}, RectCenter: {region.Rect.Center}, RectSize: {region.Rect.Size}, Angle: {region.Rect.Angle}";
FormattedText text = new FormattedText(region.Text, CultureInfo.CurrentCulture, FlowDirection.LeftToRight, new Typeface("宋体 Bold"), 12, Brushes.Black, VisualTreeHelper.GetDpi(this).PixelsPerDip);
Geometry geometry = text.BuildGeometry(new System.Windows.Point(centerX - text.Width / 2, centerY));
boxes.Children.Add(geometry);
resultLst.Items.Add(s);
}
recognizeObject.Data = boxes;这里我定义了一个名为GeometryGroup的boxes对象,表示所有识别出来的内容集合。然后遍历之前识别结果。首先在GeometryGroup里面添加矩形,这里需要注意的是识别的矩形有角度信息,需要在矩形上添加一个RotateTranform。然后添加识别出来的文字,最后将Path对象的Data设置为GeometryGroup即可。可以看到非常简单,这就是分层思路,它没有改变原来的image对象,而是把所有需要绘制的内容都放在了Path上,最后图片识别效果如下:
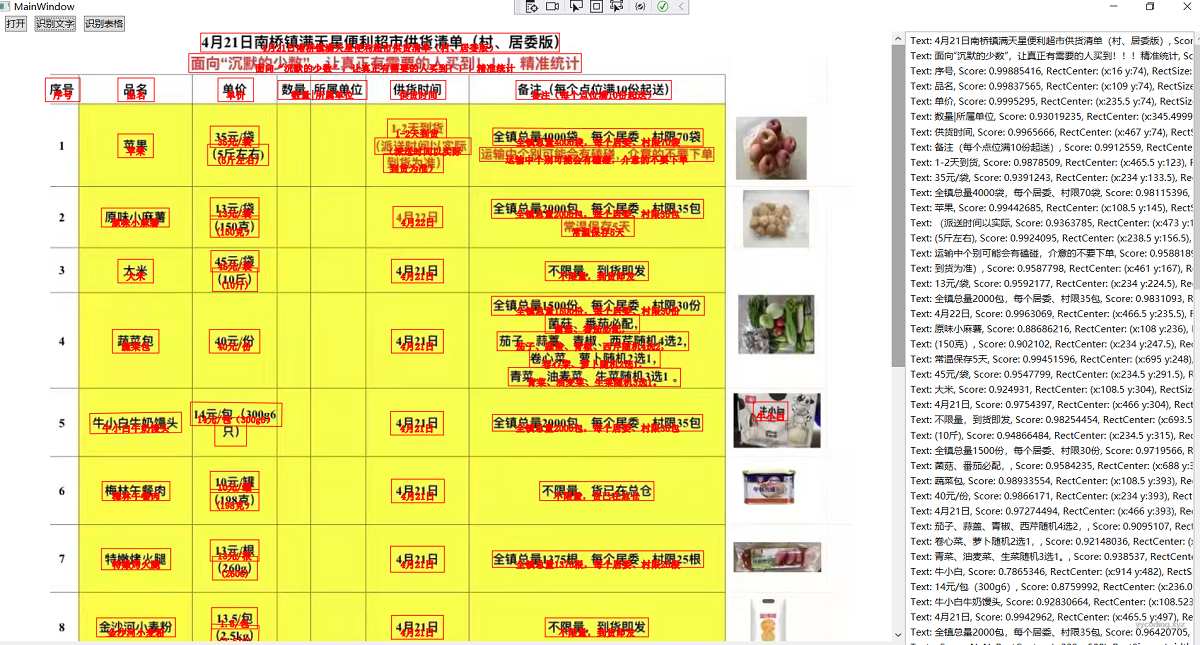 ▲PaddleOCR对图片里文字的识别效果,精度极高
▲PaddleOCR对图片里文字的识别效果,精度极高
我又找了一张我之前拍的照片:
 ▲ 可以看到,对于照片里一些比较模糊的地方,识别效果差强人意,但总体来说已经算很不错了。
▲ 可以看到,对于照片里一些比较模糊的地方,识别效果差强人意,但总体来说已经算很不错了。
这些都是对图片的整体内容识别。光能识别出内容有些时候是不够的。在有些场景下,我们需要识别图片里的特定内容,比如表格。
表格的识别
跟图片里的字符识别不同,表格识别更进一步,需要从图片里找到表格信息,这样才能对识别出来的结果进行整理。表格识别的关键是找出表格里面的行列信息。然后根据行列信息,将图片进行拆分成单个的单元格,然后对每个单元格进行字符识别。
在计算机世界,图片只是一个多维数组,如果是彩色的,它存储了RGB信息,如果是灰度图片,它存储的是亮度。一个识别图片行列的思路是,首先将图片转为灰度图,可以通过如下代码实现:
using OpenCvSharp.Mat gray = src.CvtColor(OpenCvSharp.ColorConversionCodes.RGB2GRAY);可以调用ImShow方法查看图片,这个方法在调试过程中很有用,可以直观的看到中间结果:
OpenCvSharp.Cv2.ImShow("gray", gray); 
▲ 将彩色图片转为灰度图片
然后,提取灰度图片里黑色值在180~255的区间范围,并将黑白进行翻转。
using OpenCvSharp.Mat binaryInv = gray.Threshold(180, 255, OpenCvSharp.ThresholdTypes.BinaryInv);
OpenCvSharp.Cv2.ImShow("binaryInv", binaryInv);
▲ 将灰度图片的180~255范围部分显示出来,这样过滤掉背景,并将黑白值翻转
上述binaryInv就能够用来识别列了,但如果要识别行,我们没必要选取整个图片,只需要左半部分即可,这里可以根据情况酌情考虑。要取得左半边的binaryInv,可以使用下面的语句:
using OpenCvSharp.Mat leftHalf = binaryInv[0, binaryInv.Rows, 0, binaryInv.Cols / 2];
OpenCvSharp.Cv2.ImShow("leftHalf", leftHalf); ▲binaryInv的左半边图片leftHalf,可以用来识别行
▲binaryInv的左半边图片leftHalf,可以用来识别行
有了这两幅图片,就可以在这个基础上识别出列和行了。
double[] colBlacks = GetBlacks(binaryInv, OpenCvSharp.ReduceDimension.Row);
double[] rowBlacks = GetBlacks(leftHalf, OpenCvSharp.ReduceDimension.Column);
int[] rows = CellSpan.Scan(rowBlacks, threshold: 0.9).Select(x => x.Center).ToArray();
int[] cols = CellSpan.Scan(colBlacks, threshold: 0.9).Select(x => x.Center).ToArray();
static double[] GetBlacks(OpenCvSharp.Mat src, OpenCvSharp.ReduceDimension dimension)
{
using OpenCvSharp.Mat sum = src.Reduce(dimension, OpenCvSharp.ReduceTypes.Sum, OpenCvSharp.MatType.CV_64F);
using OpenCvSharp.Mat normalized = sum.Normalize(normType: OpenCvSharp.NormTypes.INF);
normalized.GetArray(out double[] blacks);
return blacks;
}
public class CellSpan
{
private int Start, End;
public CellSpan(int start, int end)
{
Start = start;
End = end;
}
public int Length => End - Start;
public int Center => (Start + End) / 2;
public bool Contains(int v) => Start <= v && v <= End;
public static CellSpan operator +(CellSpan l, int d) => new CellSpan(l.Start + d, l.End + d);
public static CellSpan operator -(CellSpan l, int d) => new CellSpan(l.Start - d, l.End - d);
public static IEnumerable<CellSpan> Scan(double[] data, double threshold = 0.1)
{
int trackStart = -1;
for (int i = 0; i < data.Length; ++i)
{
if (trackStart == -1 && data[i] > threshold)
{
trackStart = i;
}
else if (trackStart != -1 && data[i] <= threshold)
{
yield return new CellSpan(trackStart, i);
trackStart = -1;
}
}
if (trackStart != -1)
{
yield return new CellSpan(trackStart, data.Length - 1);
}
}
}这里获取行列的主要思路就是扫描图形数组Mat对象的行和列,假设颜色深度范围为0-1,1最黑或最白,那么如果某一行或某一列的所有像素的亮度都越接近1,那么表示所在的行或列,就是表格的分隔线。
得到行或列,就可以将行和列绘制出来:
using OpenCvSharp.Mat demo = src.Clone();// binaryInv.CvtColor(OpenCvSharp.ColorConversionCodes.GRAY2RGB);
OpenCvSharp.Size size = demo.Size();
foreach (int row in rows)
{
demo.Line(0, row, size.Width, row, OpenCvSharp.Scalar.Red);
}
foreach (int col in cols)
{
demo.Line(col, 0, col, size.Height, OpenCvSharp.Scalar.Red);
}
OpenCvSharp.Cv2.ImShow("debug", demo); 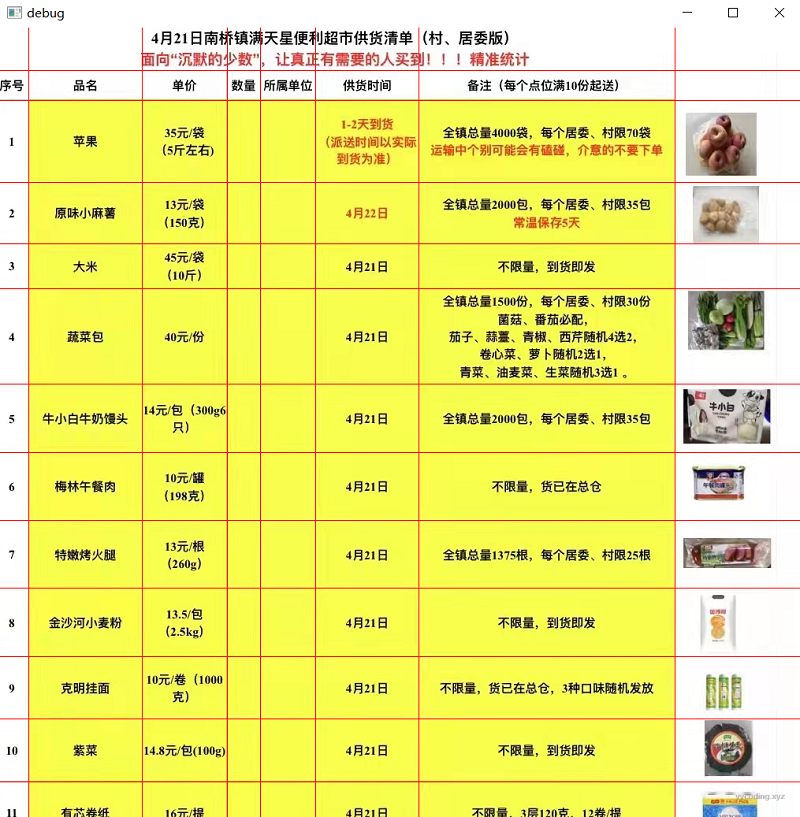
▲表格的识别,红色的线条就是根据识别的行列信息绘制的,很准确
获得行列信息后,使用行列信息,将原始图片进行切隔成单元格,下面是完整代码
OpenCvSharp.Mat[,] GetMatTable(OpenCvSharp.Mat src, bool debug = false, string debugTitle = null)
{
using OpenCvSharp.Mat gray = src.CvtColor(OpenCvSharp.ColorConversionCodes.RGB2GRAY);
OpenCvSharp.Cv2.ImShow("gray", gray);
using OpenCvSharp.Mat binaryInv = gray.Threshold(180, 255, OpenCvSharp.ThresholdTypes.BinaryInv);
OpenCvSharp.Cv2.ImShow("binaryInv", binaryInv);
using OpenCvSharp.Mat leftHalf = binaryInv[0, binaryInv.Rows, 0, binaryInv.Cols / 2];
OpenCvSharp.Cv2.ImShow("leftHalf", leftHalf);
double[] colBlacks = GetBlacks(binaryInv, OpenCvSharp.ReduceDimension.Row);
double[] rowBlacks = GetBlacks(leftHalf, OpenCvSharp.ReduceDimension.Column);
int[] rows = CellSpan.Scan(rowBlacks, threshold: 0.9).Select(x => x.Center).ToArray();
int[] cols = CellSpan.Scan(colBlacks, threshold: 0.9).Select(x => x.Center).ToArray();
if (debug)
{
using OpenCvSharp.Mat demo = src.Clone();// binaryInv.CvtColor(OpenCvSharp.ColorConversionCodes.GRAY2RGB);
OpenCvSharp.Size size = demo.Size();
foreach (int row in rows)
{
demo.Line(0, row, size.Width, row, OpenCvSharp.Scalar.Red);
}
foreach (int col in cols)
{
demo.Line(col, 0, col, size.Height, OpenCvSharp.Scalar.Red);
}
OpenCvSharp.Cv2.ImShow("debug", demo);
}
var table = new OpenCvSharp.Mat[rows.Length - 1, cols.Length - 1];
using OpenCvSharp.Mat binary = src;// ~binaryInv;
for (int yi = 0; yi < rows.Length - 1; ++yi)
{
for (int xi = 0; xi < cols.Length - 1; ++xi)
{
table[yi, xi] = binary[rows[yi] + 1, rows[yi + 1], cols[xi] + 1, cols[xi + 1]];
}
}
return table;
}紧接着,逐个单元格识别:
using (TableOCR ocr = new(all, all))
{
List<PaddleOcrResultRegion> recRegion = new List<PaddleOcrResultRegion>();
using (OpenCvSharp.Mat src = OpenCvSharp.Cv2.ImRead(imageUrl))
{
OpenCvSharp.Mat[,] matTable = GetMatTable(src, debug: true);
string[,] result = ocr.Process(matTable, cancelToken);
var boxes = new GeometryGroup();
int length1 = result.GetLength(0);
int length2 = result.GetLength(1);
for (int i = 0; i < length1; i++)
{
string linStr = "";
for (int j = 0; j < length2; j++)
{
if (j < length2 - 1)
{
linStr += result[i, j] + ",";
}
else
{
linStr += result[i, j];
}
}
resultLst.Items.Add(linStr);
}
recognizeObject.Data = boxes;
}
}该方法里面的result就是所有识别的字符串数组。TableOCR对象如下,这里面定义了中文和字符的识别模型:
public class TableOCR : IDisposable
{
PaddleOcrAll _chs;
PaddleOcrAll _eng;
public TableOCR(PaddleOcrAll chs, PaddleOcrAll eng)
{
_chs = chs;
_eng = eng;
}
public string[,] Process(OpenCvSharp.Mat[,] src, CancellationToken cancellationToken)
{
int rows = src.GetLength(0);
int cols = src.GetLength(1);
var result = new string[rows, cols];
for (int y = 0; y < rows; ++y)
{
for (int x = 0; x < cols; ++x)
{
if (cancellationToken.IsCancellationRequested) break;
OpenCvSharp.Mat cell = src[y, x];
if (y > 0 && (x == 3 || x == 4))
{
var r = _eng.Run(cell);
result[y, x] = r.Text;
}
else
{
using OpenCvSharp.Mat resized = cell.Resize(OpenCvSharp.Size.Zero, 2, 2);
var r = _chs.Run(resized);
result[y, x] = r.Text;
}
}
}
return result;
}
public void Dispose()
{
_eng.Dispose();
}
}最后的识别结果如下:
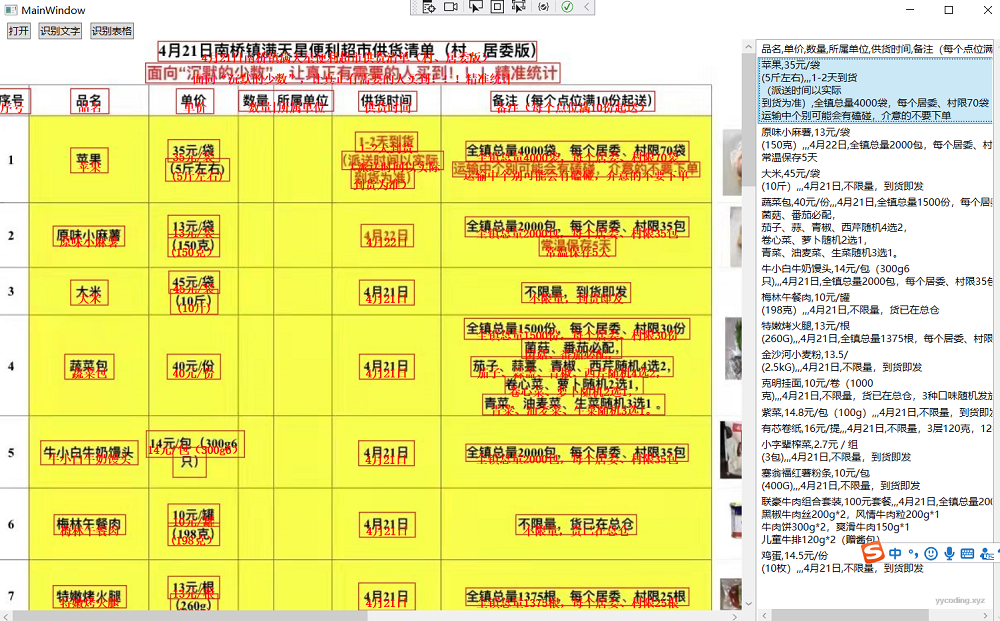 ▲ 表格的识别结果,注意右边,能准确的识别行和列数据。
▲ 表格的识别结果,注意右边,能准确的识别行和列数据。
结果的可视化
前面的例子中,如果使用的WPF,直接将一个image和一个path放在canvas里面,将识别出来的结果,绘制到GemotryGroup里面,比如矩形框(包括旋转角度),里面的文字等等,十分简单明了,它没有直接操作image,而是在path对象上绘制,这是一种分层的思想,具体的做法,可以在上面的例子中看到。
实际上,OpenCV的Mat对象也提供了一些绘制方法,包括绘制矩形,绘制文字等,比如也可以直接调用Mat对象的这些方法:
public static OpenCvSharp.Mat VisualizeTo(OpenCvSharp.Mat src, PaddleOcrResultRegion[] rects, OpenCvSharp.Scalar color, int thickness)
{
OpenCvSharp.Mat clone = src.Clone();
for (int i = 0; i < rects.GetLength(0); i++)
{
OpenCvSharp.Rect rect = rects[i].Rect.BoundingRect();
clone.Rectangle(rect, color, thickness);
clone.PutText(rects[i].Text, rects[i].Rect.Center.ToPoint(), OpenCvSharp.HersheyFonts.HersheySimplex, 0.5, color);
}
return clone;
}这里,Mat类型的clone对象,用Rectangle方法绘制矩形,这里不用考虑旋转等信息;用PutText绘制文字,这里唯一的一个严重不足是,他对中文汉字不支持,如果这里的“Text”是汉字,则会直接显示“?”,如果是英文,则能完美显示。这里对于中文信息的一个workaround就是在得到了包含有绘制信息的Mat之后,将他转回到Image对象,直接对Image对象进行操作,完了根据需要再转回Mat。可以用下面的MatToBitmap方法,将Mat转回BitmapImage显示。
public static BitmapImage MatToBitmap(OpenCvSharp.Mat matimg)
{
BitmapImage bmp = new BitmapImage();
bmp.BeginInit();
bmp.StreamSource = new MemoryStream(MatToByteArray(matimg));
bmp.EndInit();
return bmp;
}
public static byte[] MatToByteArray(OpenCvSharp.Mat mat)
{
List<byte> lstbyte = new List<byte>();
byte[] btArr = lstbyte.ToArray();
int[] param = new int[2] { 1, 80 };
OpenCvSharp.Cv2.ImEncode(".jpg", mat, out btArr, param);
return btArr;
}将Mat转为BitmapImage对象,然后在BitmapImage对象上就可以绘制中文了。
public static DrawingVisual VisualizeChinese(OpenCvSharp.Mat src, PaddleOcrResultRegion[] rects, OpenCvSharp.Scalar color, int thickness)
{
OpenCvSharp.Mat clone = src.Clone();
for (int i = 0; i < rects.GetLength(0); i++)
{
OpenCvSharp.Rect rect = rects[i].Rect.BoundingRect();//.BoundingRect;
clone.Rectangle(rect, color, thickness);
//clone.PutText(rects[i].Text, rects[i].Rect.Center.ToPoint(), OpenCvSharp.HersheyFonts.HersheySimplex, 0.5, color);
}
BitmapImage bmp = MatToBitmap(clone);
var target = new RenderTargetBitmap(bmp.PixelWidth, bmp.PixelHeight, bmp.DpiX, bmp.DpiY, PixelFormats.Pbgra32);
var visual = new DrawingVisual();
using (var r = visual.RenderOpen())
{
r.DrawImage(bmp, new System.Windows.Rect(0, 0, bmp.Width, bmp.Height));
for (int i = 0; i < rects.Length; i++)
{
double centerX = rects[i].Rect.Center.X;
double centerY = rects[i].Rect.Center.Y;
FormattedText text = new FormattedText(rects[i].Text, CultureInfo.CurrentCulture, FlowDirection.LeftToRight, new Typeface("宋体 Bold"), 14, Brushes.Red, VisualTreeHelper.GetDpi(visual).PixelsPerDip);
r.DrawText(text, new System.Windows.Point(centerX - text.Width / 2, centerY));
}
}
target.Render(visual);
return visual;
}得到DrawingVisual之后,实例化DrawingImage对象,然后直接将它赋值给Image对象的Source属性即可显示。
var item = VisualizeChinese(src, r.Regions, OpenCvSharp.Scalar.Red, thickness: 1);
var imaget = new DrawingImage(item.Drawing);
image.Source = imaget;如果要将该对象保存为图片,可以在方法VisualizeChinese返回item对象后,调用以下方法:
using (FileStream file = File.Create(postParseFileName))
{
SaveJpg(Rasterize(item.Drawing), file);
}
public System.Windows.Media.Imaging.BitmapSource Rasterize(System.Windows.Media.Drawing drawing)
{
System.Windows.Media.DrawingVisual visual = new System.Windows.Media.DrawingVisual();
using (System.Windows.Media.DrawingContext dc = visual.RenderOpen())
{
dc.DrawDrawing(drawing);
dc.Close();
}
System.Windows.Media.Imaging.RenderTargetBitmap target = new System.Windows.Media.Imaging.RenderTargetBitmap((int)drawing.Bounds.Right, (int)drawing.Bounds.Bottom, 96.0, 96.0, System.Windows.Media.PixelFormats.Pbgra32);
target.Render(visual);
return target;
}
public void SavePng(System.Windows.Media.Imaging.BitmapSource source, Stream target)
{
System.Windows.Media.Imaging.BitmapEncoder encoder = new System.Windows.Media.Imaging.PngBitmapEncoder();
encoder.Frames.Add(System.Windows.Media.Imaging.BitmapFrame.Create(source));
encoder.Save(target);
}
public void SaveJpg(System.Windows.Media.Imaging.BitmapSource source, Stream target)
{
System.Windows.Media.Imaging.BitmapEncoder encoder = new System.Windows.Media.Imaging.JpegBitmapEncoder();
encoder.Frames.Add(System.Windows.Media.Imaging.BitmapFrame.Create(source));
encoder.Save(target);
}将OCR功能加入到Excel插件
上面讲了在WPF中如何使用OCR,整个逻辑通畅之后,就可以开始把功能移植到Excel了。
第一步首先就是设计界面和逻辑。我这里的逻辑是,首先插入待识别的图片,这个功能使用Excel里面自带的插入图片也可以。
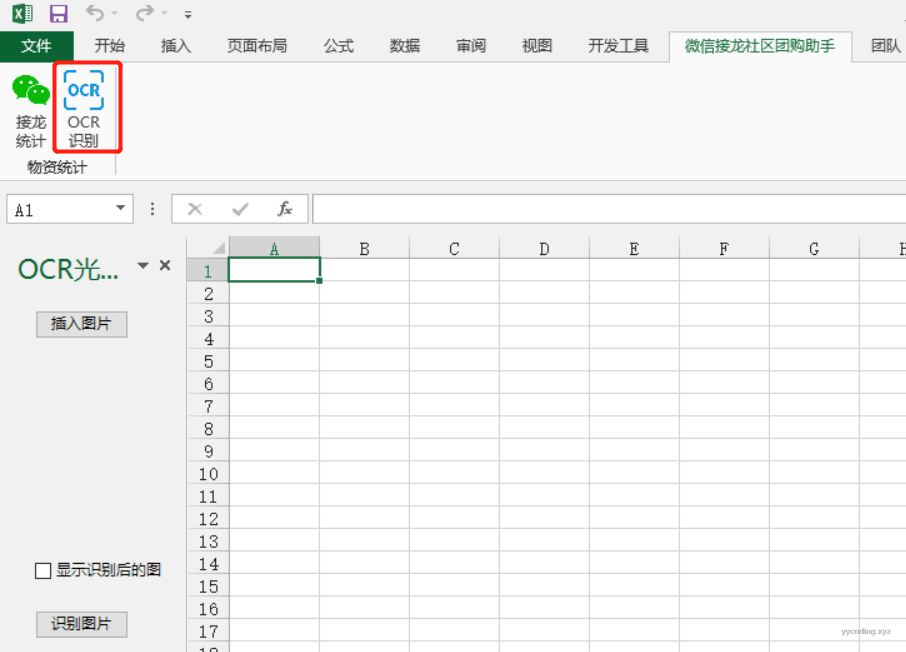 插入图片后,需要选中图片,然后点击“识别图片”按钮,如果勾选了“显示识别后的图”则会把识别内容标识到图片上(原图不受影响)。识别图片的数组结果会插入到Excel单元格里。
插入图片后,需要选中图片,然后点击“识别图片”按钮,如果勾选了“显示识别后的图”则会把识别内容标识到图片上(原图不受影响)。识别图片的数组结果会插入到Excel单元格里。
在Excel里面操作图片有一些难点。
获取插入的Excel图片对象
首先就是获取选中的Excel图片对象,我把要把这个对象转成能在OpenCV里面处理的格式,比如image文件,或者byte数组。在Excel中,获取用户选择的图像对象方法为调用Application.Selection.ShapeRange对象,需要注意的是这个属性是dynamic,当用户没有选择任何Shape对象时,访问ShapeRange对象会抛出异常,但它没提供任何判断是否有对象被选中的方法:
Worksheet sheet1 = Globals.ThisAddIn.Application.ActiveWorkbook.ActiveSheet;
ChartObjects charts = sheet1.ChartObjects();
try
{
ShapeRange selectedShapeRange = Globals.ThisAddIn.Application.Selection.ShapeRange;
int count = 0;
for (int i = 1; i <= selectedShapeRange.Count; i++)
{
//获取图形对象
Shape shape = selectedShapeRange.Item(i);
//判断是否是非预设的图形
if (shape.ShapeStyle != Microsoft.Office.Core.MsoShapeStyleIndex.msoShapeStyleNotAPreset) continue;
shape.Select();
shape.Copy();
parseFileName = System.IO.Path.Combine(AppDomain.CurrentDomain.BaseDirectory, $"{Guid.NewGuid()}.jpg");
postParseFileName = System.IO.Path.Combine(AppDomain.CurrentDomain.BaseDirectory, $"{Guid.NewGuid()}_parse.jpg");
//Save the image
System.Windows.Media.Imaging.BitmapEncoder enc = new System.Windows.Media.Imaging.JpegBitmapEncoder();
enc.Frames.Add(System.Windows.Media.Imaging.BitmapFrame.Create(System.Windows.Clipboard.GetImage()));
using (System.IO.MemoryStream outStream = new System.IO.MemoryStream())
{
enc.Save(outStream);
byte[] array = outStream.ToArray();
ParseImage(array, e);
if (e)
{
System.Drawing.Image pic = new System.Drawing.Bitmap(outStream);
pic.Save(parseFileName);
Globals.ThisAddIn.Application.ActiveWorkbook.ActiveSheet.Pictures.Insert(postParseFileName);
}
}
break;
}
}
catch (Exception ex)
{
MessageBox.Show("未选择图片");
}获得选中的图片对象之后,我们需要将Shape类型的图片对象转为能在OpenCV里面操作的内容,这里的处理方法有两种,一种是将该图片导出为jpg文件保存到磁盘上,这种方法有一个最大的缺点就是,导出的图片的质量很低,后续处理会影响识别精度。
Worksheet sheet1 = Globals.ThisAddIn.Application.ActiveWorkbook.ActiveSheet;
ChartObjects charts = sheet1.ChartObjects();
try
{
ShapeRange selectedShapeRange = Globals.ThisAddIn.Application.Selection.ShapeRange;
int count = 0;
for (int i = 1; i <= selectedShapeRange.Count; i++)
{
//获取图形对象
Shape shape = selectedShapeRange.Item(i);
//判断是否是非预设的图形
if (shape.ShapeStyle != Microsoft.Office.Core.MsoShapeStyleIndex.msoShapeStyleNotAPreset) continue;
shape.Select();
//复制图片
shape.CopyPicture();
parseFileName = System.IO.Path.Combine(AppDomain.CurrentDomain.BaseDirectory, $"{Guid.NewGuid()}.jpg");
postParseFileName = System.IO.Path.Combine(AppDomain.CurrentDomain.BaseDirectory, $"{Guid.NewGuid()}_parse.jpg");
ChartObject co = charts.Add(0, 0, shape.Width, shape.Height);
co.Chart.Paste();
//导出图形
co.Chart.Export(parseFileName, "jpg");
co.Delete();
count++;
break;
}
}
catch (Exception ex)
{
MessageBox.Show("未选择图片");
}这种导出图片的方式,要保证路径存在,另外保存出来的图片分辨率极低。
我这里的做法如上面的代码,使用WPF里面的一些BitmapEncorder,将剪贴板上的内容,转为图片,然后保存为数据流,再转为字节数组,然后处理。
这里的处理方法在ParseImage中:
private void ParseImage(byte[] imgByte, bool showTableImage)
{
System.Threading.CancellationToken cancelToken = new System.Threading.CancellationToken();
Sdcb.PaddleOCR.KnownModels.OCRModel _chs = Sdcb.PaddleOCR.KnownModels.KnownOCRModel.PPOcrV2;
_chs.EnsureAll();
using (PaddleOcrAll all = new PaddleOcrAll(_chs.RootDirectory, _chs.KeyPath)
{
AllowRotateDetection = true, /* 允许识别有角度的文字 */
Enable180Classification = false, /* 允许识别旋转角度大于90度的文字 */
})
using (TableOCR ocr = new TableOCR(all, all))
{
List<PaddleOcrResultRegion> recRegion = new List<PaddleOcrResultRegion>();
using (OpenCvSharp.Mat src = OpenCvSharp.Cv2.ImDecode(imgByte, OpenCvSharp.ImreadModes.Color))
{
if (showTableImage)
{
PaddleOcrResult r = all.Run(src);
var item = VisualizeChinese(src, r.Regions, OpenCvSharp.Scalar.Red, thickness: 1);
using (FileStream file = File.Create(postParseFileName))
{
SaveJpg(Rasterize(item.Drawing), file);
}
}
OpenCvSharp.Mat[,] matTable = GetMatTable(src, debug: showTableImage);
string[,] result = ocr.Process(matTable, cancelToken);
FastInsertValue(result);
}
}
}这里面的GetMatTable和一些方法跟前面的WPF里面的实现是一样的,可以参考。如果用户勾选了“显示识别后的图”,则生成一张识别结果的图,将结果以方框和红色字体在图片上标识出来,另外,还好存了一份没处理之前的原图:
if (showTableImage)
{
PaddleOcrResult r = all.Run(src);
var item = VisualizeChinese(src, r.Regions, OpenCvSharp.Scalar.Red, thickness: 1);
using (FileStream file = File.Create(postParseFileName))
{
SaveJpg(Rasterize(item.Drawing), file);
}
}
if (e)
{
System.Drawing.Image pic = new System.Drawing.Bitmap(outStream);
pic.Save(parseFileName);
Globals.ThisAddIn.Application.ActiveWorkbook.ActiveSheet.Pictures.Insert(postParseFileName);
}在Excel中插入图片的方法为调用Sheet的Pictures.Insert方法,传入图片的路径即可。
总结
这篇文章介绍了如何在.NET应用程序中,使用OpenCVSharp4和PaddleOCR来实现文字识别。首先使用WPF实现了图片里文字的识别,然后观察表格特征,使用OpenCV来将表格识别出来,进一步根据表格的行列信息划分为单元格,最后调用OCR识别每个单元格的内容。
在使用WPF验证了OCR的功能之后,我将该功能添加到了团购接龙的插件中,用来识别团购买菜的菜单图片文件,从中提取出了菜品的名称和价格,进一步减少了生成统计报表的工作量。
再说一下疫情,我所在的区从3月28至今,已经管控了1个月有余。在初期经历了短暂的买菜恐慌之后,随着政府主导的“满天星”社区团购的开展和志愿者的努力,基本的生活物资如米面粮油菜能得到保证。而且在一些买菜App上也能偶尔买到菜,作为本楼栋的团购买菜志愿者明显感觉到大家的买菜渠道变得更多,对政府主导的“满天星”社区团购的需求在减少,这是好事情。我所在的区最近四五天已经社会面清理(所有确诊和无症状均在管控人员中发现,风险人员筛查病例为0),小区里也没有病例,属于最早的一批无疫小区,4月29日给居民发放了通行证,凭通行证可以有条件出小区买菜。我理解社区和居委的决定,只希望整个上海的疫情能早日清零,能够恢复正常的生活状态。
 ▲4月21日本楼的团购物资,应该是最多的一次😃
▲4月21日本楼的团购物资,应该是最多的一次😃
参考
- https://stackoverflow.com/questions/36221728/how-to-check-which-shapes-objects-are-selected-active
- https://stackoverflow.com/questions/41916147/how-to-convert-system-windows-media-drawingimage-into-stream
- https://stackoverflow.com/questions/43128961/c-sharp-chart-object-from-excel-as-png-low-resolution/43143437#43143437
- https://cloud.tencent.com/developer/article/1864733
- https://social.msdn.microsoft.com/Forums/security/zh-CN/efb1c132-a57a-48ca-88a4-e030c5672f05/22914203092035129992vsto3371921462excel20013251522637722270292552
- https://github.com/sdcb/PaddleSharp
- https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/README_ch.md
- https://cloud.tencent.com/developer/article/1864733
- https://github.com/sdcb/dotnet-cv2021
感觉很高大上,能否把excel保存成xml发出来,另外把vba里边的内容放在一个code中;这样模仿起来方便一点;
有代码方便共享吗?谢谢!