Flyweight,fly是苍蝇的意思,拳击里有个“蝇量级”,翻译也是“flyweight”,在设计模式中,Flyweight被翻译成了“享元”,意思是“共享元素”。在一些需要大量小的对象的应用场景,如果想要减少内存占用,可以考虑享元模式。下面举两个例子说明。
Example 1:人名的存储
比如,在英语国家,有很多人叫“John Smith”,如果我们在系统里,就要存储这个名字很多次,那么就需要很多额外的内存来存储相同的名字。相反,如果我们能够只存储某个名字一次,然后其余的都引用这个名字,这样就会节省很多空间。
再比如,可能“Smith”这个姓有很多人用,那么就可以将名字“John”和姓“Smith”分开存储,而不是将“John Smith”整个作为FullName存储。可以将名和姓“John”和“Smith”存在一个数组中Names,然后要存储“John Smith”时,只需要存储“John”和"Smith“在数组Names中的两个下标即可。
下面这个User类是通常的做法,直接将“John Smith”整个存储成单个字符串。这就意味着“John Smith”和“Jane Smith”都是分别的字符串,他们都有自己的内存分配。
public class User
{
public string FullName { get; }
public User(string fullName)
{
FullName = fullName;
}
}现在根据上述思路,将User类构造一下,姓和名分别存储到公共的对象中。
public class User2
{
private static List<string> allNames = new List<string>();
private int[] names;
public User2(string fullName)
{
int getOrAdd(string s)
{
int idx = allNames.IndexOf(s);
if (idx != -1)
{
return idx;
}
else
{
allNames.Add(s);
return allNames.Count - 1;
}
}
names = fullName.Split(' ').Select(getOrAdd).ToArray();
}
public string FullName => string.Join(" ", names.Select(i => allNames[i]));
}这里,可以看到,定义了一个私有的静态的allNames的List集合,用来存储所有的“名”和“姓”。随后定义了一个私有的int数组,来定义本对象的“名”和“姓”在静态allNames列表里的下标。可以看到整个逻辑就完了,没有实际存储Full name字符串。只是在有需要访问到FullName的时候,才动态的根据names下标,结合allNames“姓”,“名”列表,来拼接成Full name。
这里的主要逻辑在构造函数中,在方法体内定义了一个获取“名”或者“姓”在allNames中下标的方法,如果有,直接返回下标,如果没有,追加到allNames里,并返回下标。然后将传进来的fullName,用空格分隔成“名”和“姓”,然后通过select方法,传入查找下标的委托,得到“名”和“姓‘’在整个allNames下标中的位置。
在FullName只读属性里,将下标names结合allNames大集合,用空格把“名”和“姓”拼接起来了。
这里有两个思想,非常重要,一是不存储实际字符串,而是存储在集合中的位置,二是不直接提前实现FullName,而是在需要的时候,根据存储的位置动态生成。
下面来测试一下,原文用的是dotMemory,需要安装Resharper,我试了一下很不幸,第二种方法内存占用更多🙄
using NUnit.Framework;
using JetBrains.dotMemoryUnit;
using System;
using System.Collections.Generic;
using System.Linq;
using Flyweight;
namespace Tests
{
[TestFixture]
public class Tests
{
public void ForceGC()
{
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
}
public static string RandomString()
{
Random rand = new Random();
return new string(
Enumerable.Range(0, 10).Select(i => (char)('a' + rand.Next(26))).ToArray());
}
[Test]
public void TestUser()
{
var users = new List<User>();
var firstNames = Enumerable.Range(0, 100).Select(_ => RandomString());
var lastNames = Enumerable.Range(0, 100).Select(_ => RandomString());
foreach (var firstName in firstNames)
foreach (var lastName in lastNames)
users.Add(new User($"{firstName} {lastName}"));
ForceGC();
dotMemory.Check(memory =>
{
Console.WriteLine(memory.SizeInBytes);
});
}
[Test]
public void TestUser2()
{
var users = new List<User2>();
var firstNames = Enumerable.Range(0, 100).Select(_ => RandomString());
var lastNames = Enumerable.Range(0, 100).Select(_ => RandomString());
foreach (var firstName in firstNames)
foreach (var lastName in lastNames)
users.Add(new User2($"{firstName} {lastName}"));
ForceGC();
dotMemory.Check(memory =>
{
Console.WriteLine(memory.SizeInBytes);
});
}
}
}
以上是完整代码,需要新建一个NUnit测试项目,引用JetBrains.dotMemoryUnit包,然后在测试文件里,右键,在弹出的菜单里选择“Run Unit Tests under dotMemory Unit”,就会打印出两者的内存占用,非常不幸,原始方法只占用了:7447493bit,改进方法占用了:8205631 bit。
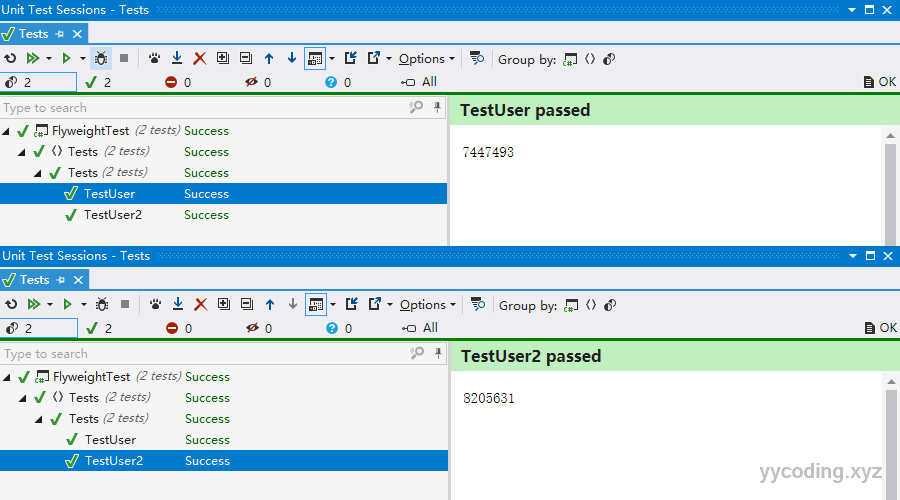
我再次使用BenchMark.DotNet来测试,代码如下:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Order;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Flyweight
{
[RankColumn]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
[MemoryDiagnoser]
public class Test
{
private static string RandomString()
{
Random rnd = new Random();
return new string(Enumerable.Range(0, 10).Select(i => (char)('a' + rnd.Next(26))).ToArray());
}
private List<string> firstNames = Enumerable.Range(0, 100).Select(i => RandomString()).ToList();
private List<string> lastNames = Enumerable.Range(0, 100).Select(i => RandomString()).ToList();
[Benchmark]
public void TestUser()
{
var user = new List<User>();
foreach (var firstName in firstNames)
{
foreach (var lastName in lastNames)
{
user.Add(new User($"{firstName} {lastName}"));
}
}
}
[Benchmark]
public void TestUser2()
{
var user = new List<User2>();
foreach (var firstName in firstNames)
{
foreach (var lastName in lastNames)
{
user.Add(new User2($"{firstName} {lastName}"));
}
}
}
}
}项目中,引用BenchmarkDotNet包,然后在要测试的地方运行如下:
using BenchmarkDotNet.Running;
using System;
namespace Flyweight
{
class Program
{
static void Main(string[] args)
{
var summary = BenchmarkRunner.Run<Test>();
Console.ReadLine();
}
}
}运行结果如下:
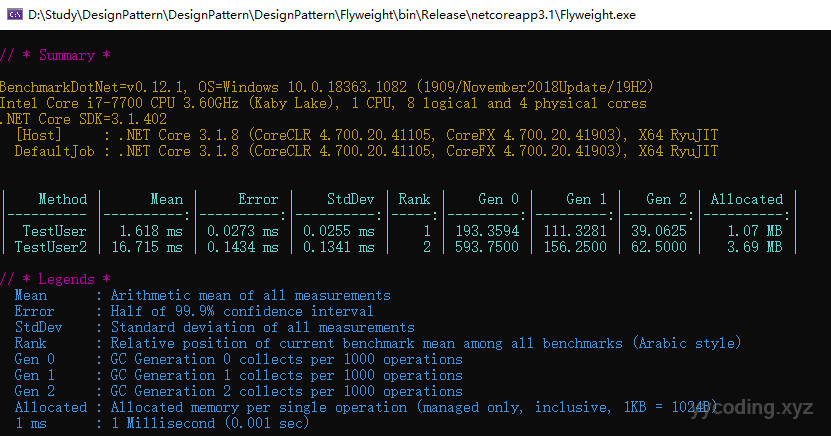
可以看到,在.NET Core 3.1下,改进后的方法,不仅占用内存多,而且运行时间也长,产生的垃圾也多。我不知道是什么问题,可能作者是用.NET来测试的,代码在Github上有,新书Design Patterns in .NET Core 3还没发布,到时候出来了可以再看下,反正意思就是这样,翻车了😂。
Example 2:字符串格式化
现在价格有个编辑器,需要将某个字符串格式化,比如,让某些字符加粗,斜体,大写等。一个方法是将这些字符串的每一个字符当做一个对象,如果某段文字包含X个字符串,就会有一个X长度的bool数组来表示某个特性,如果某个字符需要格式化,则置为true。比如,方法如下:
public class FormattedText
{
private string plainText;
private bool[] capitalize;
public FormattedText(string plainText)
{
this.plainText = plainText;
capitalize = new bool[this.plainText.Length];
}
public void Capitalize(int start, int end)
{
if ((start < 0 || start > capitalize.Length - 1) || (end < 0 || end > capitalize.Length - 1))
{
return;
}
for (int i = start; i <= end; i++)
{
capitalize[i] = true;
}
}
public override string ToString()
{
StringBuilder s = new StringBuilder(plainText.Length);
for (int i = 0; i < plainText.Length; i++)
{
var c = plainText[i];
s.Append(capitalize[i] ? char.ToUpper(c) : c);
}
return s.ToString();
}
}然后写个测试验证一下。
[TestFixture]
public class FormattedTextTest
{
[Test]
public void TestCapitalize()
{
var ft = new FormattedText("this is a new world");
ft.Capitalize(0, 3);
Assert.AreEqual(ft.ToString().Substring(0, 4), "THIS");
}
}可以看到,测试通过,通过调用Captalize,将前面三个字符,成功变成了大写。但这种方式很浪费内存,及时没有任何格式化需求,也会初始化一个capitalize数组,诚然我们可以用Lazy延迟初始化的方式,但在第一次使用时,对于特别大的文本,仍然比较费内存。
上面这个例子可以看到,我们保存了所有的字符的格式化信息,不管它有没有被用到。这种情况就特别适合享元模式,在这个例子中,我们可以定义一个Range类,来保存所有待处理的字符串的开始和结尾信息,以及需要进行格式化处理的操作。
public class TextRange
{
public int Start, End;//需要格式化的起始位置
public Func<char, char> ProcessFunc;//需要格式化的行为
public bool Covers(int position)
{
return position >= Start && position <= End;
}
}这个TextRange可以作为内部类。现在上述的Capitalize方法,我们换为GetRange方法,并返回一个TextRange类,用户可以设置一些列格式化操作,然后将这些设置好的操作保存在TextRange的集合中。当用户调用ToString的时候,一并应用上去。
public class BetterFormattedText
{
private readonly string plainText;
public readonly List<TextRange> formatting = new List<TextRange>();
public BetterFormattedText(string txt)
{
plainText = txt;
}
public TextRange GetRange(int start, int end)
{
var range = new TextRange() { Start = start, End = end };
formatting.Add(range);
return range;
}
public override string ToString()
{
var sb = new StringBuilder();
for (int i = 0; i < plainText.Length; i++)
{
var c = plainText[i];
foreach (var f in formatting)
{
if (f.Covers(i) && f.ProcessFunc != null)
{
c = f.ProcessFunc(c);
}
sb.Append(c);
}
}
return sb.ToString();
}
}需要重点看的是,ToString()里面,我们逐个检查字符串中的字符是否在格式化对象中,如果在,则应用带格式化的操作。使用方式如下:
public void TestCapitalize()
{
var bft = new BetterFormattedText("This is a brave new world");
bft.GetRange(10, 15).ProcessFunc = char.ToUpper;
Assert.AreEqual(bft.ToString(), "This is a BRAVE new world");
}非常方便,用起来也很简洁。上面的ToString()方法可能一个字符一个字符遍历可能还不够高效,但是这种方式能够节省大量内存空间。以下是对上述ToString()的改进。
public override string ToString()
{
char[] c = plainText.ToCharArray();
foreach (var f in formatting)
{
if (f.ProcessFunc != null)
{
for (int j = f.Start; j <= f.End; j++)
{
c[j] = f.ProcessFunc(c[j]);
}
}
}
return new string(c);
}总结
针对大量的细粒度对象,使用享元模式能够减少内存空间占用。享元模式有多种表现形态,比如在例1存储用户名的例子中,外部使用者根本不知道内部实现。还有一种是作为API方式返回给用户自己处理,比如BetterFormattedText里的TextRange那样。
在.NET中,类似享元模式思想的对象就是ArraySegment<T>和Span<T>了。类似前面例子中在处理字符串时的TextRange对象,Span<T>表示T数组的一部分,包含起始位置和长度。在C# 7.0中,跟ref相关的API中对Span有着大量应用。
参考