
位运算符作用于整型对象,并把运算对象看作是二进制位的集合。位运算提供了检查和设置二进制位的功能。
通常在编写代码中,相比加减乘除,位运算并不常用,但在有些情况下,位运算很有用。本文首先介绍位运算的基本概念,然后介绍位运算的应用场景,包括使用Bitmap来存储整型数据,并在此基础上介绍了如何对大量不重复的整型数据进行快速排序,对大量整型数进行去重和快速查找,最后介绍了编程语言对Bitmap思想的实现,包括C++里面的bitset,C#里面的BitArray,最后介绍了枚举值中使用位运算的一些例子。
位运算符
位运算一般作用于无符号的整型,因为如果是有符号类型,位运算符如何处理对象的“符号位”依赖于具体的机器,而且左移操作可能会改变符号位的值,因为符号位如何处理没有明确的规定,所以强烈建议仅将位运算符用于处理无符号类型。
位运算符有以下5大类,按照优先级顺序如下:
- ~:求反运算符,将运算符对象逐位求反——将1置为0、将0置为1,后生成一个新值。
- <<、>>:左移右移运算符,左移运算符<<在右侧插入值为0的二进制位,右移运算符>>。如果运算对象是无符号类型,则在左侧插入位0的二进制位;如果是有符号类型,则在左侧插入符号位的副本或者值为0的二进制位,具体要视环境而定。
- &:位与运算符,如果两个运算符对象的对应位置都是1,则运算结果中该位置为1,否则为0。
- ^:位异或运算符,如果两个运算对象的对应位置有且只有一个位是1,则结果为1,否则为0。
- |:位或运算符,如果连个运算符对象的对应位置至少有一个位是1,则运算结果为1,否则为0。
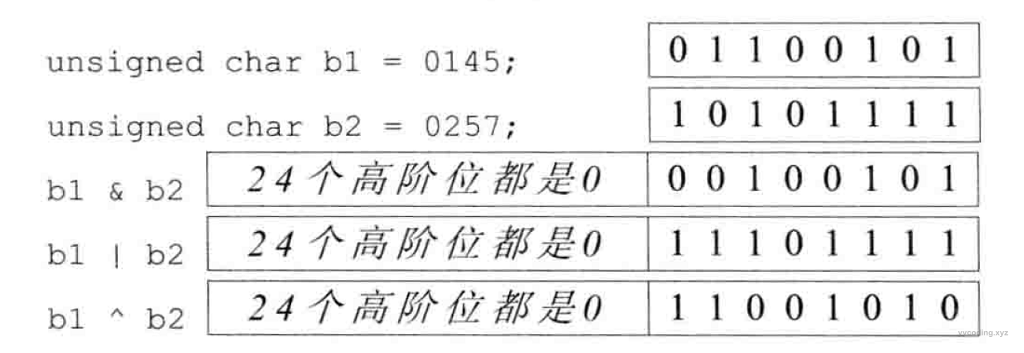
使用位运算符
这是C++ Primer里的一个例子,假设一个班级有30个人,老师每周都会对学生进行一次小检测,测验结果只有通过和不通过。可以使用一个二进制位代表某个学生在一次测验中是否通过,从右到左每一位表示一个学生,该位上的值1表示通过,0表示没通过。所以30个学生只需要一个无符号整数就可以表示。在C# 中,一个int占4个字节Bytes,1字节8位Bit,共32位。在C++中,使用:
unsigned long quizel = 0;初始化为0,将所有32个位都设置为0,表示都没通过。
- 现在假设第4位同学通过了检测,所以我们要把第4位设置为1,其它位保持不变。先构造一个只有第4位是1,其它位数都为0的32位的值,这很简单,只需要将1左移4位即可。然后将这个数,和quizel进行位或运算,然后赋值给quizel。就可以将quizel的第4位修改位1,而其它位数不变。
或者写为:quizel = quizel | (1 << 4);//将第4位置为1
因为位或运算时,只要有1个位为1,就是1,否则就是0。因为1左移4位的得到的数,只有第4是1,其它位数都是0。所以,不管quizel的第4位原先是0还是1,它与1取位或结果就是1。quizel的其它位数不管是0,还是1,与0进行或运算,结果不变,原来是0的结果还是0,原来是1的结果还是1。quizel |= (1 << 4);
- 现在假设第4位同学没有通过检测,我们需要把quizel的第4位设置为0,其它位数保持不变。同样,我们需要先构造一个只有第4位是0,其它位数是1的32的值,这也很简单,只需要将1左移4位,然后取反,就可以将第4位变为0,其它位数变为1。然后将这个数,和quizel进行位与运算,然后赋值给quizel。就可以将quizel的第4位修改位1,其它位保持不变。
因为位与运算时,只有两个都为1,才是1,否则为0。将1左移4位然后取反得到的数,第4位是0,其它位数都为1。所以,不管quizel的第4位原先是0还是1,它与0取位与运算结果就是0。quizel的其它位数不管是0还是1,与1进行位与运算,结果不变,原来是0的还是0,原来是1的结果还是1。quizel = quizel & ~(1 << 4);
- 现在假设我们不知道第4位同学的结果,需要检查第4位是0,还是1。我们先准备一个第4位是1,其它位是0的数,然后将该数与quizel取位与运算,如果quizel的第4位位1,那么位与的结果就是原先的值,否则结果就是0。我们可以直接判断结果是否为0,表示quizel原来的位置是0,否则为1;或者判断位与运算后的值是否和先前的值相等,如果相等,则为1,否则为0。
或者unsigned long result = quizel & (1 << 4); if (result) { std::cout << "the 4th student pass the quize" << std::endl; } else { std::cout << "the 4th student failed the quize" << std::endl; }unsigned long cmp = 1 << 4; result = quizel & cmp; if (cmp == result) { std::cout << "the 4th student pass the quize" << std::endl; } else { std::cout << "the 4th student failed the quize" << std::endl; }
Bitmap思想
上面的例子其实已经说明了Bitmap的概念。Bitmap的基本思想就是用一个bit位来标记某个元素对应的Value,而Key即是该元素即位的Index序号。由于采用了Bit为单位来存储数据,因此可以大大节省存储空间。
举个例子,要从20亿个随机数中找出某个数m是否存在其中,假设操作系统的内存只有4GB。在大多数语言中一个无符号整型int占4个字节(C++中整型int在16位编译器上占2个字节16位,32位编译器占4个字节32位,长整型long占4个字节32位;Java和C#中整型int占4个字节32位)。这里以C++的long长整型为例,它占4个字节共32位:
- 如果每个数字用长整型long来存储,要么内存占用为:(2000000000*4/1024/1024/1024)≈7.45G
- 如果每个数字用长整型long的bit位的index来存储,那么内存占用为:(2000000000/8/1024/1024/1024)≈0.233G
内存占用减少了32倍。原先一个long只用来存1个数,按位存储可以用来表示32个数。
数的表示
下面来详细说明如何表示一个数,前面提到一个位表示1个数,1表示存在,0表示不存在,这样很容易表示一个数组{1,2,4,7}。

上面是计算机一个字节Byte,8位Bit的表示(C++中char占1个字节,C#中byte占1个字节),从右往左,用第n位表示数字n,如果第n位的值为1,则表示存在,否则为0。所以{1,2,4,7},可以用上图的记法表示:该1个字节的第1、2、4、7位的值为1,其它位的值为0。
1个字节只有8位,只能表示数字0~7,那如果要表示{8,13,14}怎么办呢?也好办,1个字节表示不了那就用2个字节,可以放在另外一个8位上,如下图。
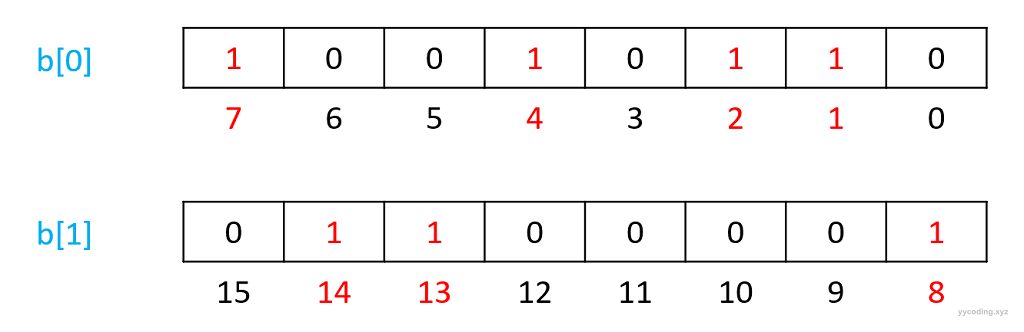
这样的话,存储结构就变成了一个二维的byte数组。
现在假设我们用int作为基本存储结构,C++中1个long占32位,所以可以存0-31这32个数,假设我们要存储的最大数为N,那么只需要申请一个long数组,长度为1+N/32即可把最大置为N的所有数存储起来:
unsigned long temp[1 + N / 32];- temp[0]可以存储0-31
- temp[1]可以存储32-63
- temp[2]可以存储64-95
- ........
所以对于给定的任意整数M,可以使用M/32就可以得到下标,表示在数组里面的第几个数,通过M%32就可以得到在下标所表示的数字里的第几位。
接下来就是添加、删除和查找操作了,这个就是前面讲过的用一个long表示30个学生,给某个学生作业设置通过(添加),不通过(删除)和检查是否通过(查找)的操作了。
添加
现在,假设要往数组{1,2,4,7}里添加数字5,怎么做呢。
首先5/32=0,5%32=5,表示5应该放在temp[0]的第5个bit位。然后把1左移5位,然后跟temp[0]进行位或操作,最后把结果赋值回temp[0]。下图只绘制了最低的8位(前面还有24位0)。
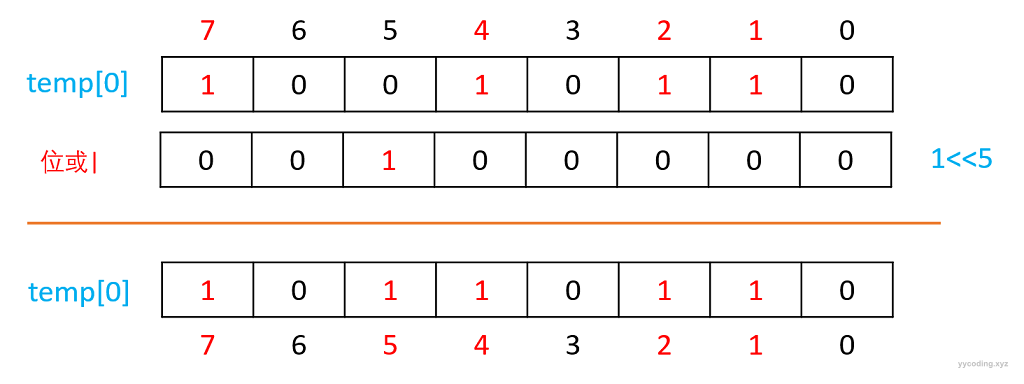
表达式为:
temp[0] = temp[0] | (1 << 5);删除
上面是添加,现在假设要删除{1,2,4,5,7}里面的元素4,如何操作呢?
首先还是公式4/32=0,4%32=4,所以我们需要将temp[0]的第4个bit位置为0。具体的操作方法是,将1往左移4位,然后取位反。得到除了第4位为0,其它位都为1的数,然后将该数与temp[0]进行位与运算,最后把结果赋值回temp[0],如下图所示:
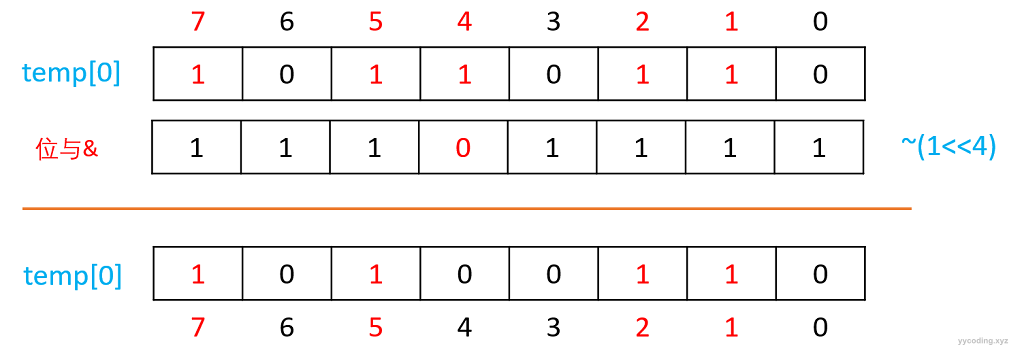
表达式为:
temp[0] = temp[0] & ~(1 << 4);查找
每个位代表一个数字,1表示该数字存在,0表示不存在,所以检查某个数字是否存在只需要判断该位是否为1。现在假设需要判断{1,2,5,7}中是否存在5。那么做法跟上面类似,首先5/32=0,5%32=5,即检查temp[0]的第5位是否为0。做法就是将1左移5位,然后将该值cmp与temp[0]进行位与操作结果为result,如果result的值为0,则表示原始数据的第5位为0,表示不存在,否则result==cmp。
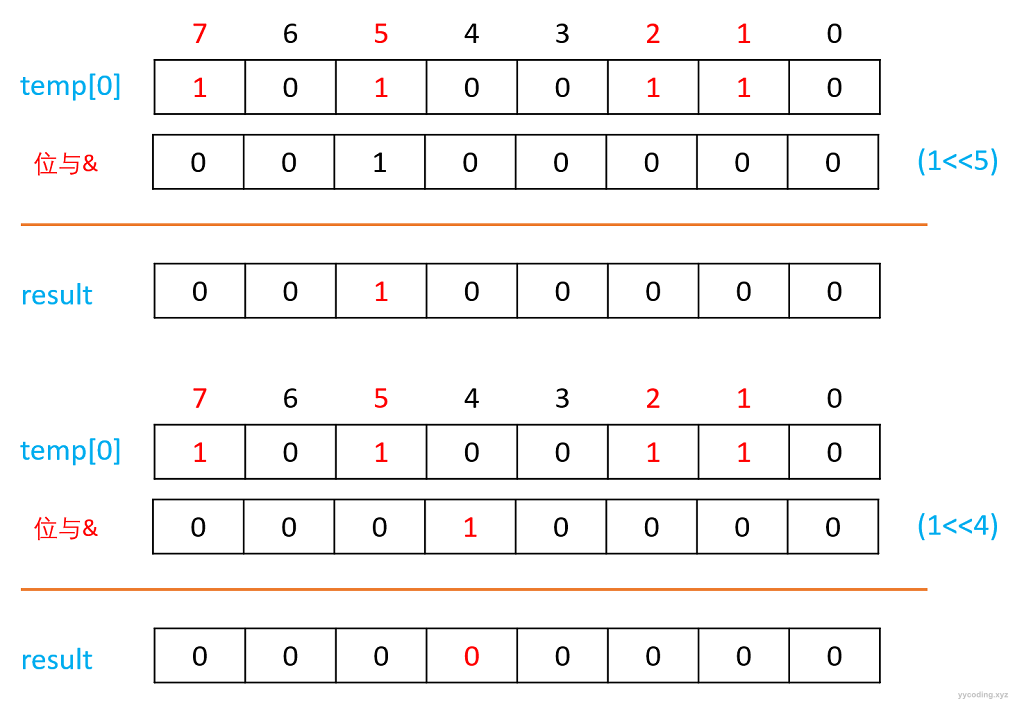
上图中可以看到 temp[0]&(1<<5)的结果不为0,结果等于(1<<5),所以表示5存在于{1,2,5,7}中。temp[0]&(1<<4)的结果为0,表示4不存在{1,2,5,7}中。
unsigned long result= temp[0] & (1 << 5);Bitmap应用
上面说明了Bitmap存储数据的原理,相比使用基础数据结构存储每一个数据,使用位的index来存储数据能够节省大量的存储空间。除存储之外,在大数据量的排序,查找和去重方面,Bitmap也有很大的优势。
快速排序
如果用Bitmap来存储数,那么快速排序就变得很简单了,因为数据是按位的先后顺序排列的,比如要排序{2,5,1,7},只需要做的是,将该序列存储到Bitmap中,存储后的结果如下:

此时只需要从低位向高位依次遍历,取出该位置位为1的index,并输出即可,方法如PrintSort所示。
#include <iostream>
void SetBit(unsigned int &item, const int i)
{
item = item | (1 << i);
}
void ClearBit(unsigned int &item, const int i)
{
item = item & ~(1 << i);
}
bool CheckBit(const unsigned int &item, const int i)
{
return (item & (1 << i)) != 0;
}
void PrintSort(const unsigned int &item)
{
auto t = sizeof(item);
auto length = t * 8;
std::cout << "print ascend order of item" << std::endl;
for (size_t i = 0; i < length; i++)
{
if (CheckBit(item, i))
{
std::cout << i << " ";
}
}
std::cout << std::endl;
}
int main()
{
unsigned int bitmap = 0;
SetBit(bitmap, 2);
SetBit(bitmap, 5);
SetBit(bitmap, 1);
SetBit(bitmap, 7);
PrintSort(bitmap);
return 1;
}这种方法它的优点是:
- 运算效率高,时间复杂度为O(n),不需要进行复杂的比较运算
- 内存占用少,对于N个数,只需要N/8个字节Byte的内存空间,比如当N=1000万时,只有10000000/8/1024/1024=1.25M的内存空间占用。
但它也有缺点:
- 只能适用于无符号的整型对象,因为位的index是正整数,所以要求待操作排序的对象必须是正整数
- 数据不能存在重复,对重复的数,无法进行排序和查找,因为一个位只能有一个Index,只能存放一个值。
- 只有当数据比较密集分布时才有优势,比如对于一个只有2个数的序列{1,1000000},很显Bitmap相比普通的排序,在时间和空间效率上都要差很多。
快速去重
比如要找出20亿个不重复的数的个数,或者输出不重复的数。
这个问题很简单,我们只需要一次将这20亿个数存入到Bitmap,首先找到需要存储的位数index。
- 如果该index位的值为0,则写入1
- 如果该index位的值为1,表示之前该数已经出现过,忽略
然后,遍历整个Bitmap的所有位:
- 如果该位的值位0,忽略,检查下一位
- 如果该位的值位1
- 如果要求输出不重复的数,此时打印该位所在的index即可。
- 如果要求统计不重复的数的个数,此时count+=1即可。
去重的复杂度也为O(n)。
查找
查找就更简单了,直接判断待查找的值,所在的数(n/size)以及该数中的位(n%size)的值是否位1,如果为1即存在,否则不存在,时间复杂度为O(1)。
编程语言中的实现
前面Bitmap的思想,在C++中的标准库提供了bitset类型,在Java中为BitSet;在C#中则提供了System.Collections.BitArray和System.Collections.Special.BitVector32类,两者区别在于BitArray是类类型,而BitVector32是值类型,如果只需要存储32位,则BitVector32效率更高并且占用内存更少;
C++中的bitset
在C++中,bitset在于标准库bitset中:
#include "bitset"
std::bitset<32> bset;
bset.set(2, true);
bset.set(5, true);
bset.set(1, true);
bset.set(7, true);
bset.reset(1); // remove 1
std::cout << "bset contains " << bset.count() << " values" << std::endl;
std::cout << "bset size " << bset.size() << std::endl;
for (size_t i = 0; i != bset.size(); i++)
{
if (bset[i])
{
std::cout << i << " ";
}
}set方法用来设置该位的值为true还是false,reset方法用来将该位的值设置为false,count为bitset中所有不为0的位数;size为可存储的总位数。
C#中的BitArray
在C#中,BitArray在System.Collections中:
System.Collections.BitArray bitArray = new BitArray(32, false);
bitArray.Set(2, true);
bitArray.Set(5, true);
bitArray.Set(1, true);
bitArray.Set(7, true);
Console.WriteLine("bitArray lenght " + bitArray.Length);
for (int i = 0; i < bitArray.Length; i++)
{
if (bitArray[i])
{
Console.Write(i + " ");
}
}BitArray的Set实现源码如下:
// You can define other methods, fields, classes and namespaces here
/*=========================================================================
** Sets the bit value at position index to value.
**
** Exceptions: ArgumentOutOfRangeException if index < 0 or
** index >= GetLength().
=========================================================================*/
public void Set(int index, bool value)
{
if (index < 0 || index >= Length)
{
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
}
Contract.EndContractBlock();
if (value)
{
m_array[index / 32] |= (1 << (index % 32));
}
else
{
m_array[index / 32] &= ~(1 << (index % 32));
}
_version++;
}
/*=========================================================================
** Returns the bit value at position index.
**
** Exceptions: ArgumentOutOfRangeException if index < 0 or
** index >= GetLength().
=========================================================================*/
public bool Get(int index)
{
if (index < 0 || index >= Length)
{
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
}
Contract.EndContractBlock();
return (m_array[index / 32] & (1 << (index % 32))) != 0;
}可以看到,BitArray在内部是使用一个32位数组来保存的,对于任何一个数index,对应的数组内的元素为index/32,需要将1左移的位数为index%32。
- 如果要将该位的值设置为true,等同于将该位的值设置为1,就是将该对象和1左移index%32位后,进行位或操作,然后将结果赋值到该对象。
- 如果要将该位的值设置为false,等同于将该位的值设置为0,就是将该对象和1左移index%32位后取反,进行位与操作,然后将结果赋值到该对象。
Get方法在内部判断该数值与1左移index%32位取位与操作后的结果,如果不等于0则表示该处的值为1,返回true,否则返回false。这跟前面介绍的算法一模一样。
其它应用
位运算除了在Bitmap中应用之外,还有一些地方会用到位运算。
算术应用
在没有数字溢出的情况下,左移一位相当于乘以2,右移一位相当于除以2。左移n位就相当于乘以2的n次方,右移n位相当于除以2的n次方。
- << 左移:相当于乘以2的n次方,例如:1<<6 相当于1×64=64,3<<4 相当于3×16=48
- >> 右移:相当于除以2的n次方,例如:64>>3 相当于64÷8=8
- ^ 异或:相当于求余数,例如:48^32 相当于 48%32=16
- 判断奇偶性:可以判断最低为是0还是1,0就是偶数,1就是奇数。因此可以用if ((a & 1) == 0)代替if (a % 2 == 0)来判断a是不是偶数。
- 取一个数的指定位数:比如取数 X=1010 1110 的低4位,可以用另外一个数Y,使Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行按位与运算(X&Y=0000 1110)即可得到X的指定位
- 对一个数据的某些位设置为1:比如将数 X=1010 1110 的低4位设置为1,可以用另外一个数Y,使Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行按位或运算(X|Y=1010 1111)即可得到
- 翻转指定位:比如将数 X=1010 1110 的低4位进行翻转,可以用另外一个数Y,令Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行异或运算(X^Y=1010 0001)即可得到。
- 使一个数的最低位为零:使a的最低位为0,可以表示为:a & ~1。~1的值为 1111 1111 1111 1110,再按"与"运算,最低位一定为0。
枚举
在多数语言中,可以定义枚举类型,枚举类型在底层是一个整型。比如在C#中,枚举默认使用int来表示,但是我们可以指定其类型,比如下面的枚举类型LogLevel我们指定其类型位byte。枚举的第一个值默认从0开始。
[Flags]
public enum LogLevel:byte
{
NONE = 0,
DEBUG = 1,
INFO = 2,
WARNING = 4,
ERROR = 8,
EXCEPT = 16,
CRITICAL = 32,
}枚举可以添加Flags标识符。
- 当可以对枚举值进行位操作时,可以添加Flags标记。
- 当要进行位运算时,需要将枚举的项定义为2的n次方,也可以直接写为1<<n位。因为会常量求值,这种写法比定义为0、1、2、4、8更清晰明了。
- 当向变量添加某个枚举值时,使用位或运算符。比如当我们需要记录INFO和WARNING级别的日志时,可以定义为。
它相当于将两个项相加,值为3,但是对于标记为Flags的枚举,输出的字符串为DEBUG|INFO,更加友好。LogLevel debugInfoLevel=LogLevel.DEBUG|LogLevel.INFO;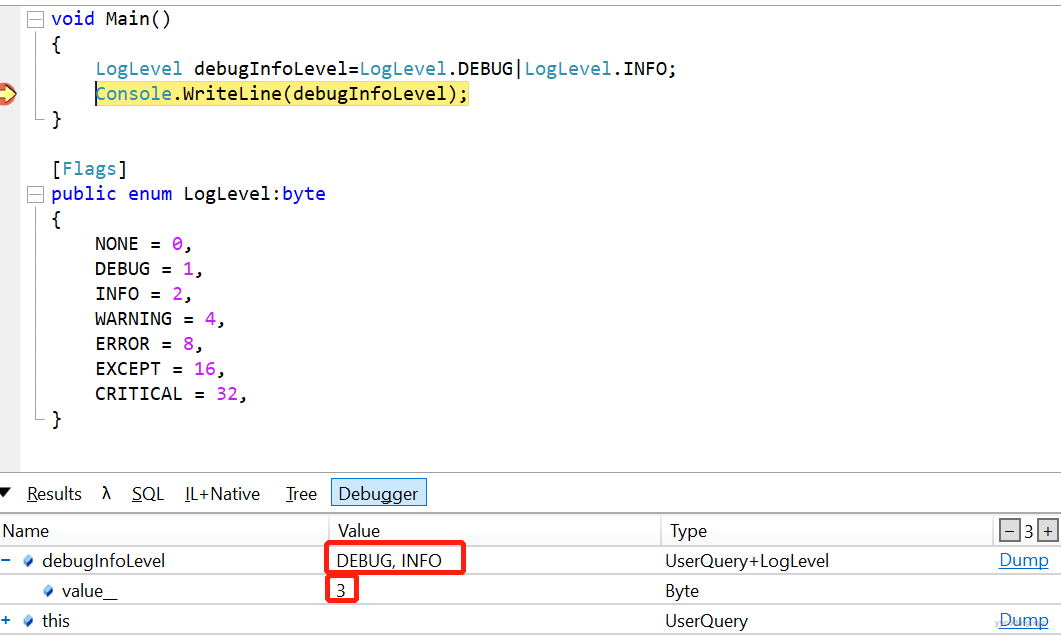
- 当从某个变量中移除某个枚举值时,可以使用该值和需要移除的枚举值进行异或运算^或者对需要移除的枚举值取反~然后进行位与运算&。
LogLevel debugInfoLevel = LogLevel.DEBUG | LogLevel.INFO; LogLevel debug = debugInfoLevel ^ LogLevel.INFO; Console.WriteLine(debug); LogLevel anotherDebug = debugInfoLevel & ~LogLevel.INFO; Console.WriteLine(anotherDebug); - 判断某个枚举变量是否包含特定的枚举值,可以使用HasFlag方法,比如要判断上面的debugInfoLevel是否包含有INFO标记,可以使用:
LogLevel debugInfoLevel = LogLevel.DEBUG | LogLevel.INFO; if (debugInfoLevel.HasFlag(LogLevel.INFO)) { Console.WriteLine("debugInfoLevel has INFO."); }它等同于,将一个变量与某一个项进行位与操作,如果跟某个项相等,则表示包含有该权限。
LogLevel debugInfoLevel = LogLevel.DEBUG | LogLevel.INFO; if ((debugInfoLevel & LogLevel.INFO) == LogLevel.INFO) { Console.WriteLine("debugInfoLevel has INFO."); } if ((debugInfoLevel & LogLevel.ERROR) != LogLevel.ERROR) { Console.WriteLine("debugInfoLevel does not have ERROR."); }
其它
比如不使用用第三方变量交换两个值:
// 方式一
a = a + b;
b = a - b;
a = a - b;
// 方式二
a = a ^ b;
b = a ^ b;
a = a ^ b;
参考
https://www.cnblogs.com/cjsblog/p/11613708.html
https://mp.weixin.qq.com/s/m43L_xHvOr6DsepbR2A1LA
https://www.cnblogs.com/huangxincheng/archive/2012/12/06/2804756.html
https://mp.weixin.qq.com/s/f74WddTTKsEKP0s_2hUHwQ
https://mp.weixin.qq.com/s/INeQ1_AekYgry17BNNFQuw
https://learn.microsoft.com/zh-cn/dotnet/api/system.collections.specialized.bitvector32?view=net-6.0
https://learn.microsoft.com/en-us/dotnet/api/system.enum?view=net-6.0