

前一段时间在优化行情数据系统,整个系统的大概流程是从第三方数据服务商获取行情数据,然后通过专门的网络传输到自有的服务器上进一步分析处理。由于网络带宽有限,随着行情源数据流量的不断增大,有必要对流量进行优化,所以需要对数据传输流进行压缩,以减少数据传输过程中的数据流量。
最开始使用的C#里面内置GZip压缩算法,将二进制转换为流,然后压缩传输。现在需要去调研一下有没有更好的压缩算法,我这里记录一下我的解决思路。
为什么需要压缩
压缩在本质上,就是将数据换一种方式来进行存储,比如一种最常见的思路是:如果数据里面重复的内容比较多,那么可以简单的将这些重复的内容只记录一次,然后用其它字段记录该内容的存储位置。一般来说,数据的重复越多,压缩的效果就越好。
不同的领域,处理的数据特性不同。比如在股票行情领域,它属于时序数据,数据冗余度和相似度较高,天然适合进行压缩。比如下面某一时刻某只股票的行情:
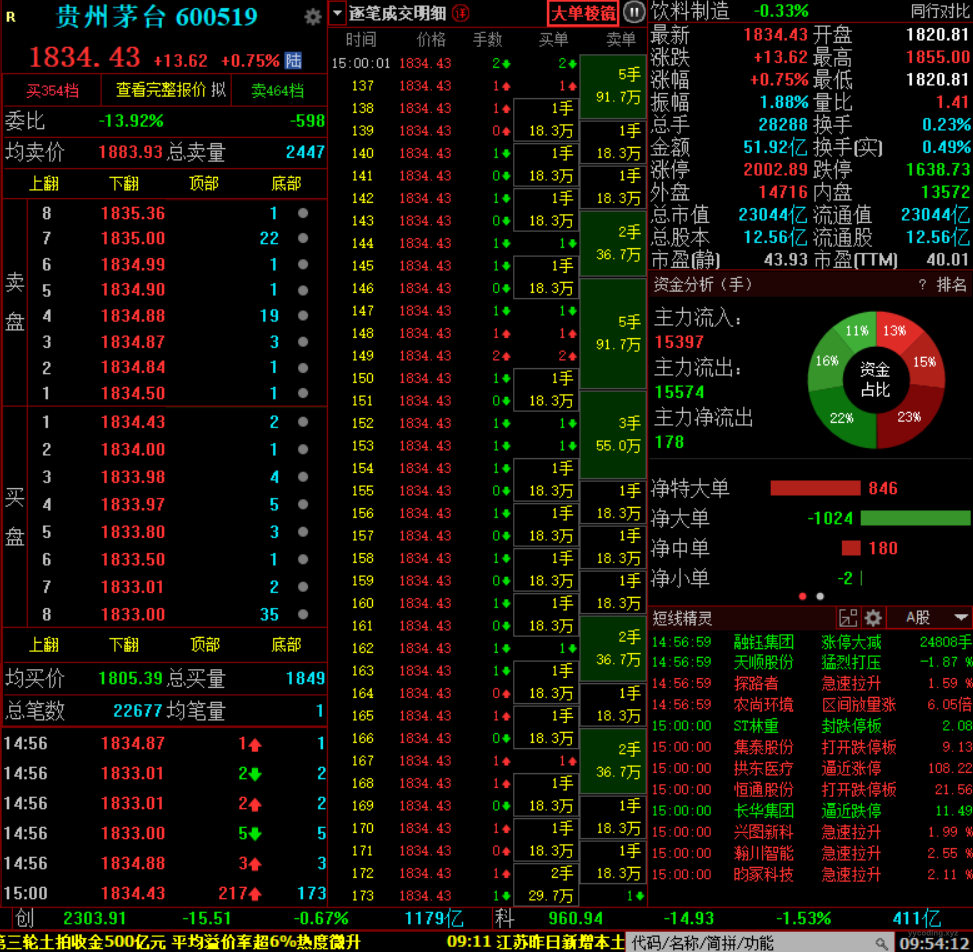 ▲ 某一时刻,某只股票的行情信息
▲ 某一时刻,某只股票的行情信息
可以看到,在买卖十档数据中,有很多重复数字,比如价格里面的1834,前面两位或者三位基本都是一样的,再比如在逐比成交里面,有大量相同的成交价格。另外,T时刻与T+1时刻的数据,可能也有很多重复。假如在这一段时间内,没有交易产生,那么T和T+1时刻的数据就会是一样的。
因此,这种时序数据,天然适合进行压缩,压缩能极大的减少数据量。
当然,压缩和解压是需要耗费时间的,但是整个行情系统的时间它实际上是包括数据处理加上传输的时间,如果数据处理阶段能够通过消耗一定的时间减少数据量,那么在数据传输时间就能极大的减少数据传输的耗时,整体上是能够提升效率的。
选取压缩算法需要考虑的因素
压缩算法有很多,可以按照不同的特性进行划分,比如无损压缩和有损压缩,无损压缩是指压缩后能够解压回原来的数据,数据质量不会丢失,在行情数据的处理过程中,很明显需要采用无损压缩算法。有损压缩是指压缩后,数据精度可能会有损失,不能够复原,比如最常见的是图片的处理,将图片从高分辨率处理为低分辨率、大图片调整为小图片,这种调整是不可逆的,从低分辨率调整为高分辨,数据精度和质量就会丢失。
另外需要考虑的就是压缩比和压缩时间。这本质上是一种时间和空间的矛盾。一些压缩算法压缩解压快,但是压缩率低;一些算法压缩解压慢,但是压缩率比较高。在有些场景下,对时间比较敏感,所以就可以选取压缩解压耗时小的算法,比如实时行情处理,它对时间有极高的要求;而有些场景对时间不敏感,但对空间很敏感,比如如果要将历史行情数据进行落地存储,因为数据量大磁盘空间有限,所以需要选择压缩率比较高的算法以节约磁盘空间。
另外,被压缩数据块的大小可能也会对压缩时间和压缩率产生影响,比如对过小的数据进行压缩,可能压缩后的体积比压缩前还要大。所以需要考虑压缩数据的大小对同一压缩算法在压缩率方面的影响。
比较和分析
除了GZip压缩算法之外,需要寻找能供使用的其它无损压缩算法。有两个思路:
- 一种是将关键字转换为对英文支持较好的搜索引擎比如Google去查找。比如我这里需要的是无损压缩算法,所以可以使用“lossless compression algorithm”作为关键字去搜索,在确定好算法之后,可以进一步看是否有对应的.NET版本。一般都会有,这些压缩算法为求高效率一般会使用C或者C++编写,.NET可以通过P/Invoke技术非常方便与其它类库进行互操作,所以常用的比较流行的算法都会有.NET的版本,不论是原生实现还是对其它类库的包装。
- 第二种方法就是直接在Github上,使用以上关键字去搜索。
经过一番查找,我找到了以下几种无损压缩算法:
- GZip,这种已经是内置的,但它有两种实现,一种是.NET内置的System.IO.Compression.GZipStream,现有的系统使用的就是这种;还有一种是第三方的实现SharpZipLib。
- Zstd是facebook开源的提供高压缩比的快速压缩算法,读做Zstandard。它是一种快速的无损压缩算法,主要应用于 zlib 级别的实时压缩方案,并且具有更好的压缩比。它还可以以压缩速度为代价提供更强的压缩比,速度与压缩率可配置,是一项性能优秀的压缩技术,与 zlib、lz4、xz 等压缩算法不同,Zstd 寻求的是压缩性能与压缩率通吃的方案。针对Zstd的.NET包装有ZstdNet类库,它使用P/Invoke对Zstd库进行了封装,目前版本是1.4.5,它是对Zstd 1.4.5版本的封装。Zstd有更新的版本,直接用最新的Zstd版本放到ZstdNet类库下面也能直接使用,因为签名没有发生变化。
- Lz4压缩算法是由YannCollet在2011年设计实现的,lz4属于lz77系列的压缩算法。lz77严格意义上来说不是一种算法,而是一种编码理论,它只定义了原理,并没有定义如何实现。lz4是目前基于综合来看效率最高的压缩算法,更加侧重于压缩解压缩速度,压缩比并不突出,本质上就是时间换空间。它的.NET实现有K4os.Compression.LZ4。
- Snappy 是一个 C++ 的用来压缩和解压缩的开发包。其目标不是最大限度压缩或者兼容其他压缩格式,而是旨在提供高速压缩速度和合理的压缩率。Snappy 比 zlib 更快,但文件相对要大。Snappy 在 Google 内部被广泛的使用,从 BigTable 到 MapReduce 以及内部的 RPC 系统,他的.NET实现是snappy.net。
需要注意的是,因为.NET平台有很多版本,由于当前系统使用的是.NET 4.5,所以上面的.NET版本采用的都是.NET 4.5或者兼容.NET 4.5版本。在测试之前,新建一个接口,提供压缩解压方法:
public interface ICompressor
{
byte[] Compressor(byte[] data);
byte[] Decompressor(byte[] data);
}然后就是各种不同算法的实现类,它们都实现这个接口。下面分别是.NET内置的GZip、ISharpZipLib的GZip、ZStd、Lz4、和Snappy的实现:
public class MSGZip : ICompressor
{
public byte[] Compressor(byte[] data)
{
using (var ms = new MemoryStream())
{
using (var gzipstream = new GZipStream(ms, CompressionMode.Compress))
{
gzipstream.Write(data, 0, data.Length);
}
return ms.ToArray();
}
}
public byte[] Decompressor(byte[] data)
{
using (var ms = new MemoryStream(data))
{
using (var gzs = new GZipStream(ms, CompressionMode.Decompress))
{
using (var outBuf = new MemoryStream())
{
gzs.CopyTo(outBuf);
return outBuf.ToArray();
}
}
}
}
}
public class SharpZipGzip : ICompressor
{
public byte[] Compressor(byte[] data)
{
using (var ms = new MemoryStream())
{
using (var gzipstream = new GZipOutputStream(ms))
{
gzipstream.Write(data, 0, data.Length);
}
return ms.ToArray();
}
}
public byte[] Decompressor(byte[] data)
{
using (var ms = new MemoryStream(data))
{
using (var gzs = new GZipInputStream(ms))
{
using (var outBuf = new MemoryStream())
{
gzs.CopyTo(outBuf);
return outBuf.ToArray();
}
}
}
}
}
public class ZStd : ICompressor
{
private Compressor compressor = new Compressor();
private Decompressor decompressor = new Decompressor();
public byte[] Compressor(byte[] data)
{
return compressor.Wrap(data);
}
public byte[] Decompressor(byte[] data)
{
return decompressor.Unwrap(data);
}
}
public class LZ4 : ICompressor
{
public byte[] Compressor(byte[] data)
{
return LZ4Pickler.Pickle(data);
}
public byte[] Decompressor(byte[] data)
{
return LZ4Pickler.Unpickle(data);
}
}
public class Snappy : ICompressor
{
public byte[] Compressor(byte[] data)
{
using (var ms = new MemoryStream())
{
using (var gzipstream = new SnappyStream(ms, System.IO.Compression.CompressionMode.Compress))
{
gzipstream.Write(data, 0, data.Length);
}
return ms.ToArray();
}
}
public byte[] Decompressor(byte[] data)
{
using (var ms = new MemoryStream(data))
{
using (var gzs = new SnappyStream(ms, System.IO.Compression.CompressionMode.Decompress))
{
using (var outBuf = new MemoryStream())
{
gzs.CopyTo(outBuf);
return outBuf.ToArray();
}
}
}
}
}有了以上方法之后,我们需要为每个需要测试的项目来新建测试类,比如我这里需要测试,压缩率、压缩时间、压缩解压时间,所以分别新建了三个类CompressorRatioBenchMark、CompressorTimeBenchMark、CompressorDecompressorTimeBenchMark,这些类大同小异,我这里以测试压缩率的CompressorRatioBenchMark类来说明:
public class CompressorRatioBenchMark
{
private int zipCount = 1;
List<byte[]> testDatas = new List<byte[]>();
private bool useByteArrayCompressor = true;
public CompressorRatioBenchMark(DataFeedDataType dateType, int zcount = 1, int dataCount = 1, bool useByteArrayCompressor = true)
{
this.useByteArrayCompressor = useByteArrayCompressor;
zipCount = zcount;
for (int i = 0; i < zipCount; i++)
{
byte[] b = TestSendData.GetTestData(dateType, dataCount);
testDatas.Add(b);
}
}
public double MSGZip()
{
ICompressor zip = new MSGZip();
return TestCompressorRatio(zip);
}
public double SharpZipGzip()
{
ICompressor zip = new SharpZipGzip();
return TestCompressorRatio(zip);
}
public double ZStd()
{
ICompressor zip = new ZStd();
return TestCompressorRatio(zip);
}
public double LZ4()
{
ICompressor zip = new LZ4();
return TestCompressorRatio(zip);
}
public double Snappy()
{
ICompressor zip = new Snappy();
return TestCompressorRatio(zip);
}
private double TestCompressorRatio(ICompressor compressor)
{
double totalOriginal = 0;
double totalZipped = 0;
for (int i = 0; i < testDatas.Count; i++)
{
byte[] original = testDatas[i];
totalOriginal += original.Length;
if (useByteArrayCompressor)
{
byte[] zipeed = compressor.Compressor(original);
totalZipped += zipeed.Length;
}
else
{
byte[] zipeed = compressor.CompressorStream(original);
totalZipped += zipeed.Length;
}
}
return totalZipped / totalOriginal;
}
}构造函数里有一些参数,第一个DataType表示数据类型,比如我这里有Level2快照数据、逐比成交数据、全速盘口数据类型,这些类型对应不同的单个测试数据格式,最主要是大小不同。第二个参数是测试次数,比如测试10次,那么就是随机生成10份数据,进行压缩,然后取平均值,第三个参数是单个数据类型的大小,比如我这里设置为2,那么就是把2两个DataType表示的数据类型,拼成一个byte[]数组,这个要用到BlockCopy:
public static byte[] Combine(byte[] first, byte[] second)
{
byte[] ret = new byte[first.Length + second.Length];
Buffer.BlockCopy(first, 0, ret, 0, first.Length);
Buffer.BlockCopy(second, 0, ret, first.Length, second.Length);
return ret;
}最后一个参数表示是用二进制数组还是流进行压缩,我这里只演示了对二进制数组的压缩。如果要测试流的压缩,需要在接口中添加新的方法,各个类里面也需要添加相应的实现。
实现了上面三个类之后,需要增加一个管理类BenchMarkManual,用来统筹测试项目:
public enum CompressorCategory
{
Ratio = 1,
CompressionTime = 2,
CompressionAndDecompressionTime = 3
}
public class ResultInfo
{
public static string GetDisplayHeader()
{
return $"DataType,CompressionCategory,DataCount,CompressorTimes,GZip,SharpZiGzip,ZSTD,LZ4,Snappy";
}
public DataFeedDataType DataType;
public int DataCount;
public int CompressorTimes;
public CompressorCategory CompressionCategory;
public double GZip;
public double SharpZiGzip;
public double ZSTD;
public double LZ4;
public double Snappy;
public override string ToString()
{
return $"{DataType},{CompressionCategory},{DataCount},{CompressorTimes},{GZip},{SharpZiGzip},{ZSTD},{LZ4},{Snappy}";
}
}
public class BenchMarkManual
{
private bool useByteArrayCompression;
private DataFeedDataType dtype;
private int dataCount;
private bool warmUp;
private int comptimes;
public BenchMarkManual(DataFeed.DataFeedDataType dataType, int times, int dc, bool useBinary)
{
useByteArrayCompression = useBinary;
dtype = dataType;
comptimes = times;
dataCount = dc;
warmUp = true;
CompressionRatio();
CompressionTime();
CompressionAndDecompressionTime();
warmUp = false;
}
public ResultInfo CompressionRatio()
{
ResultInfo result = new ResultInfo();
result.CompressionCategory = CompressorCategory.Ratio;
result.DataType = dtype;
result.DataCount = dataCount;
result.CompressorTimes = comptimes;
CompressorRatioBenchMark rate = new CompressorRatioBenchMark(dtype, comptimes, dataCount, useByteArrayCompression);
double msgzip = rate.MSGZip();
double sharpZipGzip = rate.SharpZipGzip();
double lz4 = rate.LZ4();
double zstd = rate.ZStd();
double snoopy = rate.Snappy();
if (!warmUp)
{
string compressorMethod;
if (useByteArrayCompression)
{
compressorMethod = "bytearray";
}
else
{
compressorMethod = "memorystream";
}
Console.WriteLine($"{dtype}(size*{dataCount}) :avg compress rate ({comptimes} times) use {compressorMethod} compressor method:");
Console.WriteLine("gzip:" + msgzip);
Console.WriteLine("sharpzip_gzip:" + sharpZipGzip);
Console.WriteLine("lz4:" + lz4);
Console.WriteLine("zstd:" + zstd);
Console.WriteLine("snappy:" + snoopy);
Console.WriteLine("***********************************");
result.GZip = msgzip;
result.SharpZiGzip = sharpZipGzip;
result.LZ4 = lz4;
result.ZSTD = zstd;
result.Snappy = snoopy;
}
return result;
}
public ResultInfo CompressionTime()
{
ResultInfo result = new ResultInfo();
result.CompressionCategory = CompressorCategory.CompressionTime;
result.DataType = dtype;
result.DataCount = dataCount;
result.CompressorTimes = comptimes;
CompressorTimeBenchMark rate = new CompressorTimeBenchMark(dtype, comptimes, dataCount, useByteArrayCompression);
double msgzip = rate.MSGzip();
double sharpZipGzip = rate.SharpZipGzip();
double lz4 = rate.LZ4();
double zstd = rate.ZSTD();
double snoopy = rate.Snappy();
if (!warmUp)
{
string compressorMethod;
if (useByteArrayCompression)
{
compressorMethod = "bytearray";
}
else
{
compressorMethod = "memorystream";
}
Console.WriteLine($"{dtype}(size*{dataCount}):avg compress time ({comptimes} times) ticks use {compressorMethod} compressor method:");
Console.WriteLine("gzip:" + msgzip);
Console.WriteLine("sharpzip_gzip:" + sharpZipGzip);
Console.WriteLine("lz4:" + lz4);
Console.WriteLine("zstd:" + zstd);
Console.WriteLine("snappy:" + snoopy);
Console.WriteLine("***********************************");
result.GZip = msgzip;
result.SharpZiGzip = sharpZipGzip;
result.LZ4 = lz4;
result.ZSTD = zstd;
result.Snappy = snoopy;
}
return result;
}
public ResultInfo CompressionAndDecompressionTime()
{
ResultInfo result = new ResultInfo();
result.CompressionCategory = CompressorCategory.CompressionAndDecompressionTime;
result.DataType = dtype;
result.DataCount = dataCount;
result.CompressorTimes = comptimes;
CompressorUnZipTimeBenchMark rate = new CompressorUnZipTimeBenchMark(dtype, comptimes, dataCount, useByteArrayCompression);
double msgzip = rate.MSGzip();
double sharpZipGzip = rate.SharpZipGzip();
double lz4 = rate.LZ4();
double zstd = rate.ZSTD();
double snoopy = rate.Snappy();
if (!warmUp)
{
string compressorMethod;
if (useByteArrayCompression)
{
compressorMethod = "bytearray";
}
else
{
compressorMethod = "memorystream";
}
Console.WriteLine($"{dtype}(size*{dataCount}) :avg compress-decompress time ({comptimes} times) milliseconds use {compressorMethod} compressor method:");
Console.WriteLine("gzip:" + msgzip);
Console.WriteLine("sharpzip_gzip:" + sharpZipGzip);
Console.WriteLine("lz4:" + lz4);
Console.WriteLine("zstd:" + zstd);
Console.WriteLine("snappy:" + snoopy);
Console.WriteLine("***********************************");
result.GZip = msgzip;
result.SharpZiGzip = sharpZipGzip;
result.LZ4 = lz4;
result.ZSTD = zstd;
result.Snappy = snoopy;
}
return result;
}
}构造函数里,需要提供待测试的数据类型、测试次数、测试数据的大小倍数,以及是否采用二进制数组压缩解压。其中针对每一项提供了一个函数。
最后,在Mian函数里,直接调用:
class Program
{
static string fileName = "Result.txt";
static void Main(string[] args)
{
List<string> lines = new List<string>();
lines.Add(ResultInfo.GetDisplayHeader());
BenchMarkManual manual;
for (int i = 1; i <= 100; i++)
{
manual = new BenchMarkManual(DataFeed.DataFeedDataType.FastLevel2, 1000, i, true);
ResultInfo result = manual.CompressionRatio();
lines.Add(result.ToString());
result = manual.CompressionTime();
lines.Add(result.ToString());
result = manual.CompressionAndDecompressionTime();
lines.Add(result.ToString());
}
if (System.IO.File.Exists(fileName))
{
File.Delete(fileName);
}
System.IO.File.WriteAllLines(fileName, lines);
Console.ReadLine();
}
}我这里,对FastLevel2全速盘口这一数据类型,大小倍数从1测试到100,每次测试1000次取平均,然后将运行结果输出到txt文件,然后在Excel里面对比分析。
结果分析
以上程序运行结束后,会将结果输出到txt文件,使用Excel打开txt就可以分析。
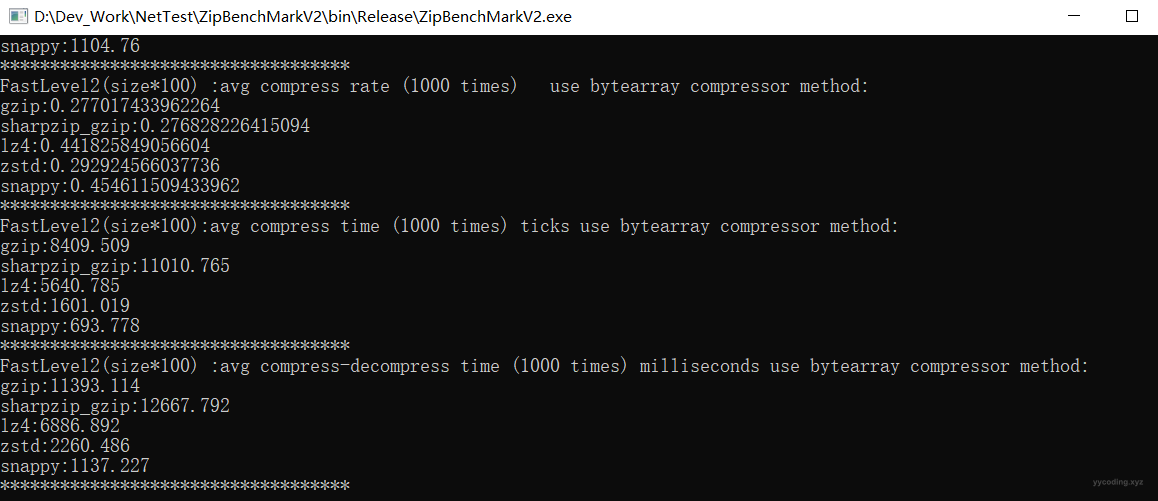 ▲ 程序运行界面
▲ 程序运行界面
在对结果进行分析,并制图后,可以看到以下结果:
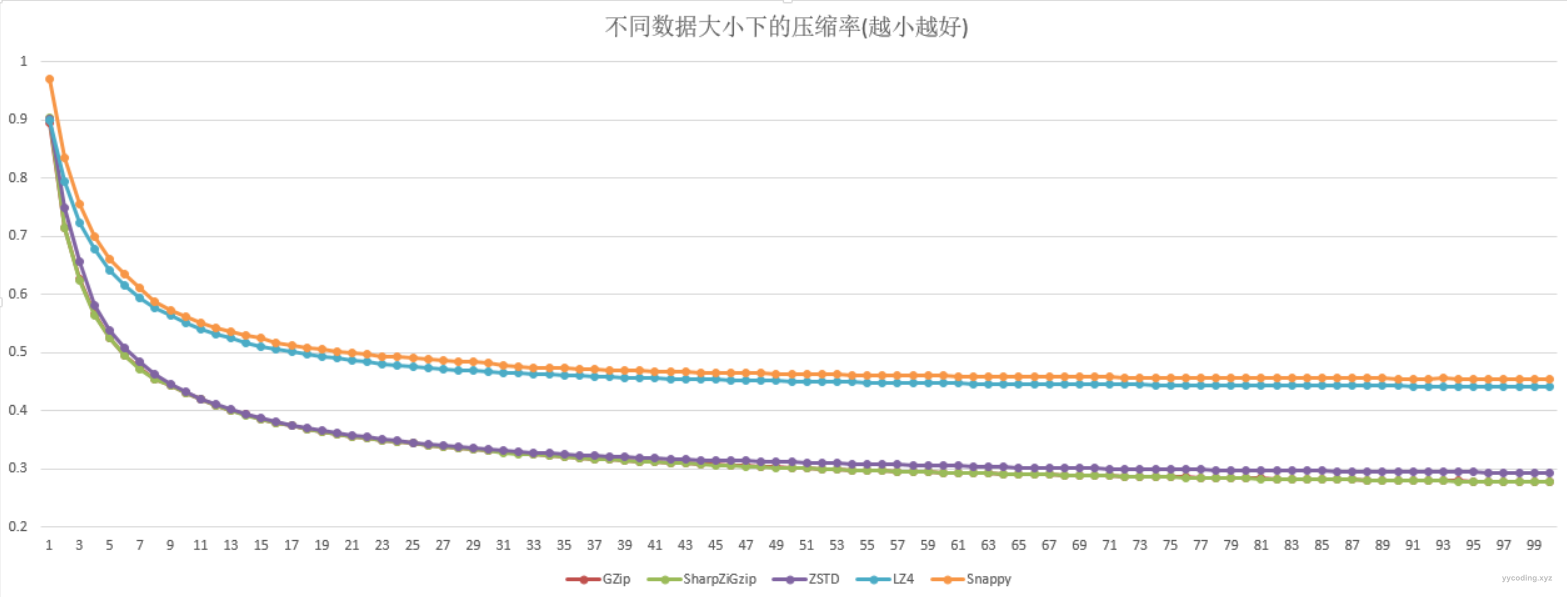
▲不同FastLevel2倍数大小下,不同算法的压缩率(压缩后大小/压缩前大小,越小越好)
可以看到在压缩率方面,GZip和SharpZipGzip以及Zstd是在一组,LZ4和Snappy在一组,总体而言,前者比后者压缩率要好很多。C#内置的GZip实现、与SharpZip的实现,两者在压缩率方面比较接近,基本差不多。当Size变大时,GZip和SharpZip整体压缩率率比Zstd稍好,大概在9~10倍的FastLevel2大小时,两者比较接近。

▲不同FastLevel2倍数大小下,不同算法的压缩耗时(单位tick,越小越好)
在压缩耗时方面,可以看到前面压缩率比较差的Snappy则表现的非常好,压缩很快,且随着压缩数据的大小增大,压缩时间增长也比较缓慢。Zstd表现也很好,曲线比较平缓。C#内置和SharpZip实现的GZip算法,在压缩时间方面耗时则比较长,并且随着数据Size的增大,压缩耗时增加也比较明显。这里可以看到C#内置的GZip实现,比SharpZipLib的实现,在压缩时间方面,要优秀很多。

▲不同FastLevel2倍数大小下,不同算法的压缩解压耗时(单位tick,越小越好)
在压缩和解压总耗时方面,整体跟单独的压缩耗时差不多。依然是Snappy最优,Zstd也相当优秀,两个GZip的实现比较耗时,且SharpZipLib比内置的更耗时。
总体而言,在对全速盘口行情的压缩方面,Zstd算法在压缩率方面与GZip接近,在9-10倍的FastLevel2大小时,两者压缩效率基本相等。但Zstd在兼顾压缩率的同时,压缩时间也比较短,且当数据大小增大时,耗时增加也比较平缓。总体而言,在这四个算法中,Zstd效果最好。
需要提醒的是,对于ZstdNET这个类库,它提供了两种方法,一种是直接对二进制数组进行压缩解压,
byte[] Wrap(byte[] src);
byte[] Unwrap(byte[] src, int maxDecompressedSize = int.MaxValue);一种是对数据流进行压缩解压:
CompressionStream(Stream stream);
DecompressionStream(Stream stream);前者是后者效率的10倍还多(差别可能是二进制算法是在Wrap类里对使用P/Invoke对Native dll进行了一次直接调用,数据流方法则在Wrap类内部进行了多次的P/Invoke调用),所以如果要使用,尽量使用二进制数组的压缩解压方法。
总结
需要说明的是,本文只是针对特定的平台:NET Framework 4.5、特定的测试数据:股票的极速Level2数据来进行不同压缩算法的相对效率比较。并且没有使用BenchmarkDotNet这种专业的性能分析工具来对比分析,其原因是限于.NET Framework 4.5平台的限制,BenchmarkDotNet最新的版本并不支持.NET Framework 4.5,如果使用4.5版本,则缺少一些特性,比如我需要的除了运行时间之外,还需要压缩率这种指标,在BenchmarkDotNet支持4.5的版本里还没找到如何实现。一个标准的测试,需要考虑线程优先级,垃圾回收对结果的影响,这些因素我没有考虑,但是这样的影响对所有的算法则都一样,且我是测试了1000次求平均得出的结果,所以应该是具有参考意义的。另外在Github上,EasyCompressor这个项目使用BenmarkDotNet比较了.NET Core平台下各种压缩效率,它得出的结论也是Zstd最好,有兴趣的可以看看。
针对行情数据这种时序数据,本文分析了几种无损压缩算法,分别是内置的GZip、SharpZipLib的GZip实现、Zstd、LZ4和Snappy。在对比后发现,Zstd具有比较好的压缩率,同时也能有比较好的压缩速度,在这几种算法中最能满足情数据处理以及传输效率的要求。
参考
- https://github.com/facebook/zstd
- https://facebook.github.io/zstd/
- https://github.com/skbkontur/ZstdNet
- https://www.cnblogs.com/t-bar/p/16506289.html
- https://www.cnblogs.com/buttercup/p/16414046.html
- https://www.codenong.com/415291/
- https://zhuanlan.zhihu.com/p/414871190
- https://github.com/mjebrahimi/EasyCompressor
- https://github.com/lz4/lz4
- https://github.com/MiloszKrajewski/K4os.Compression.LZ4
- https://github.com/dotnet/BenchmarkDotNet
- https://mp.weixin.qq.com/s/kbSdt8tRT4EtmxyYuj_dHA