
根据运算符在变量的前面还是后面,可以分为前置(prefix)运算符和后置(postfix)运算符。++i、--i就是前置运算符,i++、i--就是后置运算符。
前置i,++i是先将变量 i 的值加 1,然后再使用这个新值进行计算或赋值操作;后置i,i++则是先使用变量i的原始值进行计算或者赋值,然后再将i的值加1。
在C#中,前置式和后置式++或--,似乎除了语义上的区别之外,效率上没有区别,但在C++中则不一样,《Primer C++》和 《More Effective C++》中都说明,前置式自增自减(++i、--i)的效率比后置式(i++、i--) 通常更快,且至少不慢(prefix will sometimes be faster but never slower then postfix)。
在C语言中,前置式和后置式在性能上没有区别,i++可能(potentially)会比++i慢,因为在i++中,需要先使用i的值,所以需要先存储i的值到变量temp中,然后再把i增加,最后返回temp的值即i自增之前的值,这显然会增加消耗。但现代的编译器会把这种差别优化掉。比如下面这两条语句,以编译器的智商,完全可以把第一个i++优化为第二个的++i的形式:
for (int i = 0; i < 100; i++)
{
// do something
}
for (int i = 0; i < 100; ++i)
{
//do something
}所以在C++中,对于基本类型比如int类型,前置和后置的效率没有差别,但对于C++中自定义的类(class),前置运算符的效率至少不低于后置运算符(sometimes be faster but never slower)。在C++中前置和后置自增自减运算是通过运算符重载来实现的。
在看C++中的自增自减重载之前,先看看C#中的自增自减运算符。
C#中重载自增自减运算符
在C#中,自增自减运算符也是通过重载实现的,但自增自减操作符的重载没有前置和后置的区分,其方法签名只有一种。但如何正确在C#实现自增自减重载也有需要注意的地方,否则就会出现不符合前置后置式运算的表现。在.NET源码中可以看到int类型的自增自减实现,但我没有找到其它类类型的重载,如果找到了可以参考实现。这里先看C#中int的表现:
[TestMethod]
public void TestIncrement()
{
int c = 10;
Assert.AreEqual(c, 10);
Assert.AreEqual(c++, 10);
Assert.AreEqual(c, 11);
c = 10;
Assert.AreEqual(c, 10);
Assert.AreEqual(++c, 11);
Assert.AreEqual(c, 11);
}上述单元测试显而易见能够通过(这里简化了单元测试的写法,应该写到多个test case中)。n++相当于以下操作:
int temp = n;
n = n + 1;
return temp;而++n则相当于:
n = n + 1;
return n;现在,假设我们定义一个类,来模拟int类型,我们就起名为CSharpInt,使用方法跟int一样,我们要求他表现的行为跟内置的int类型默认的前置后置自增自减的行为一样,即:
[TestMethod]
public void TestIncrement()
{
CSharpInt c = new CSharpInt(10);
Assert.AreEqual(c, 10);
Assert.AreEqual(c++, 10);
Assert.AreEqual(c, 11);
c = new CSharpInt(10);
Assert.AreEqual(c, 10);
Assert.AreEqual(++c, 11);
Assert.AreEqual(c, 11);
}那么这个CSharpInt如何实现,下面这个模仿“后置式”的语意实现:
public class CSharpInt
{
private int number;
public CSharpInt(int _i)
{
number= _i;
}
public static CSharpInt operator ++(CSharpInt i)
{
CSharpInt temp = new CSharpInt(i.number);
++i.number;
return temp ;
}
/// <summary>
/// 隐式类型转换,方便将CsharpInt对象转换为int类型
/// </summary>
/// <param name="d"></param>
public static implicit operator int(CSharpInt d) => d.number;
public override string ToString()
{
return number.ToString();
}
}上述CSharpInt的实现中,内部使用一个int对象来保存数字,自增的重载只有一种,并不区分前置和后置,统一的签名方法为:
public static CSharpInt operator ++(CSharpInt i)必须是静态方法,返回类型和参数都是待重载的对象,方法前名为“operator ++”。
这里的实现模仿后置自增的方法,先创建一个新的temp对象(因为这是一个class是引用类型),用参数的值来初始化temp,然后返回该对象,接着将参数的值自增。
public static CSharpInt operator ++(CSharpInt i)
{
CSharpInt temp = new CSharpInt(i.number);
++i.number;
return temp;
}现在运行单元测试 ,发现失败了:

上面的实现,是的i++返回的值我们期望的是i的原始值10,而不是++之后的值11,单元测试的结果显示,这显然跟我们想要的不符。
现在改用“前置式”的语义,直接修改参数,然后返回修改后的参数对象:
public static CSharpInt operator ++(CSharpInt i)
{
++i.number;
return i;
}再次运行单元测试,会发现结果跟之前的没有任何区别。
那如何才能正确的重载自增操作符呢?正确的做法是:
- 不要修改参数的值,确保操作没有副作用(side effect),这就要求在方法内部必须深度拷贝参数对象。
- 既然没有区别前置和后置操作符,所以只需要在拷贝后的对象上,执行自增自减操作,然后返回修改后的拷贝对象即可,不需要考虑前置后置的语义区别。
- 前置后置的语意区别由编译器来完成,即i++和++i的行为由编译器来负责处理。
按照以上准则,CSharpInt自增操作符的正确做法如下:
public static CSharpInt operator ++(CSharpInt i)
{
//拷贝对象,并对该对象执行递增操作,然后返回该拷贝后的对象
CSharpInt c = new CSharpInt(i.number + 1);
return c;
}再次运行单元测试,会发现测试通过。
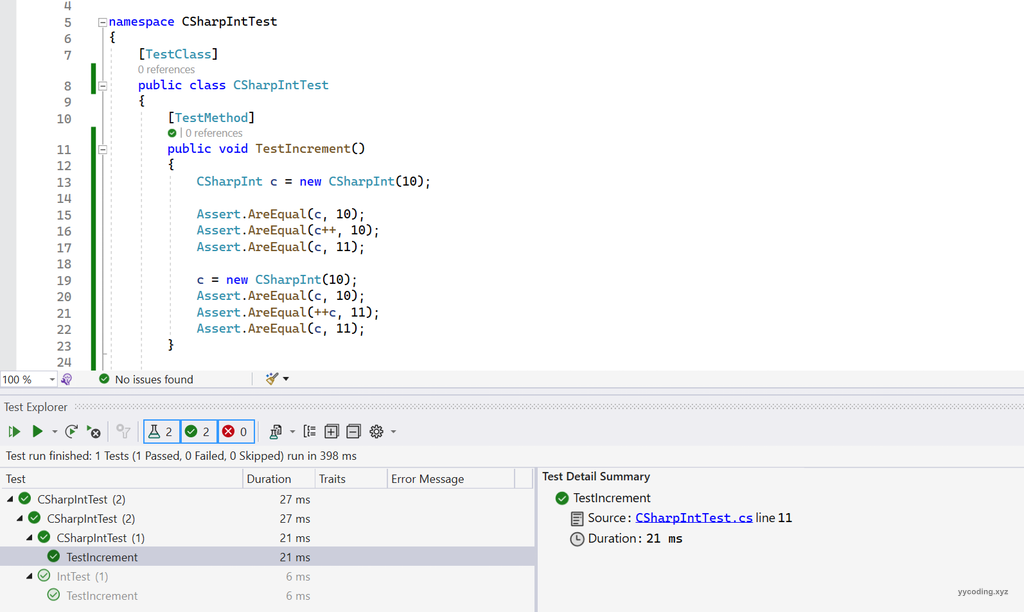
额外说明一下,之所以能将CSharpInt类型和int类型直接进行比较,是因为CSharpInt对象有隐式类型转换,它的实现如下:
/// <summary>
/// 隐式类型转换,方便将CsharpInt对象转换为int类型
/// </summary>
/// <param name="d"></param>
public static implicit operator int(CSharpInt d) => d.number;这种隐式类型转换在C++也有,后面有机会再说。
上面只重载了自增运算符,自减运算符也类似:
public static CSharpInt operator --(CSharpInt i)
{
CSharpInt c = new CSharpInt(i.Number - 1);
return c;
}或者
public static CSharpInt operator --(CSharpInt i)
{
CSharpInt c = new CSharpInt(i.Number);
--c.Number;
return c;
}这里我们调用了内置int类型的前置自减运算符。
C++中重载前置后置自增自减运算符
在C++中,要重载前置后置自增自减运算符就比较讲究了,在《More Effective C++》中甚至有专门的条款6来说明如何正确重载自增自减运算符。
重载方法是通过参数类型来区分彼此的,但前置和后置重载都没有参数,所以为了解决这个问题,C++只好在后置式上添加了一个int参数(对你没有看错,这种骚操作在C++能够经常看到),在被调用时,编译器默默地为该参数指定一个0值。在C++中,重载前置和后置的自增自减运算符的代码如下:
#include <iostream>
class UPInt
{
public:
friend std::ostream &operator<<(std::ostream &os, const UPInt &ui);
UPInt(uint32_t t = 0) : i(t){}; // 构造函数
UPInt &operator++(); // 前置式 ++
const UPInt operator++(int); // 后置式++
UPInt &operator--(); // 前置式 --
const UPInt operator--(int); // 后置式--
UPInt &operator+=(int); // 重载+=
UPInt &operator-=(int); // 重载-=
private:
int32_t i;
};使用方法如下:
UPInt i(10);
++i;//调用i.operator++() 前置自增
i++;//调用i.operator++(0) 后置自增
--i;//调用i.operator--() 前置自减
i--;//调用i.operator--(0) 后置自减除了函数参数之外,函数的返回值也有区别,前置式返回对象的引用,后置式返回一个常量对象。
自增操作符的前置式的含义是“累加然后取出”(increment and fetch),后置式的含义是“取出然后累加”(fetch and increment),这就是前置式和后置式操作符正确实现的规范。在上面的UInt对象中,自增操作的前置和后置式的实现如下:
UPInt &UPInt::operator++()
{
*this += 1; //累加 increment
return *this; //取出 fetch
}
const UPInt UPInt::operator++(int)
{
UPInt old = *this; //取出 fetch
++(*this); //累加 increment
return old; //返回先前取出的值
}在后置式里并没有使用int参数,这个参数如前所述,其作用仅用来区分前置式和后置式而已。
为什么后置式要返回一个对象(代表旧值),原因和清楚。但为什么是const常量呢?常量表示返回的这个对象不能被修改。如果不是常量,下面的操作就是合法的。
UPInt i(10);
i++++;后置运算符调用了两次,它相当于
i.operator++(0).operator++(0)operator++(0)的第二个动作施加到第一个调用动作的返回值上。这里面会有两个问题:
- 它和内建的int类型的行为不相符,int不允许连续两次调用++运算符,即i++++是非法的,但++++i是合法的。
- 即使能够实施两次后置自增,它的结果也不是我们想要的,第二个operator++(0) 所改变的是第一个operator++(0)所返回的对象,而不是原对象,所以即使i++++合法,i也只是被累加一次。所以这违反直觉,容易造成混乱,所以做好的办法就是禁止这样使用。
C++禁止了int类型连续两次调用operator++(0),所以我们自己设计的类UPInt需要手动加以禁止,办法就是让后置式返回const类型的对象。所以当编译器看到i++++时,发现第一次调用operator++(0)返回的是const对象,它被用来第二次调用operator++(0),但operator++(0)是一个非常量的成员函数,所以常量对象无法调用非常量成员函数。
后置式的自增自减也有效率问题,因为它返回的是旧对象,所以必须先创建一个临时对象来作为返回值使用,临时对象也需要构造和解析,这就有性能损耗,但前置式则没有这个顾虑。所以除非就是需要使用后置式的含义(后面会介绍一个例子),否则最好使用前置式。
最后一个问题是,前置式和后置式都是对对象进行自增或自减,那么如何保证他们内部的行为一致呢?一个原则是,以前置式为基础,在后置式里面调用前置式,这样只需要维护一个前置式的实现即可。在后置式的实现中,可以看到“ ++(*this); ”这句代码,就是去调用前置式的实现。
const UPInt UPInt::operator++(int)
{
UPInt old = *this; //取出 fetch
++(*this); //累加 increment
return old; //返回先前取出的值
}最后完整的UPInt声明级实现如下:
#include <iostream>
class UPInt
{
public:
friend std::ostream &operator<<(std::ostream &os, const UPInt &ui);
UPInt(uint32_t t = 0) : i(t){}; // 构造函数
UPInt &operator++(); // 前置式 ++
const UPInt operator++(int); // 后置式++
UPInt &operator--(); // 前置式 --
const UPInt operator--(int); // 后置式--
UPInt &operator+=(int); // 重载+=
UPInt &operator-=(int); // 重载-=
private:
int32_t i;
};
UPInt &UPInt::operator+=(int t)
{
i += t;
return *this;
}
UPInt &UPInt::operator-=(int t)
{
i -= t;
return *this;
}
std::ostream &operator<<(std::ostream &os, const UPInt &ui)
{
os << ui.i;
return os;
}
UPInt &UPInt::operator++()
{
*this += 1;
return *this;
}
const UPInt UPInt::operator++(int)
{
UPInt old = *this;
++(*this);
return old;
}
UPInt &UPInt::operator--()
{
*this -= 1;
return *this;
}
const UPInt UPInt::operator--(int)
{
UPInt old = *this;
--(*this);
return old;
}一个需要使用后置式而不是前置式的场景
虽然大部分情况下,考虑到性能问题(内置类型性能差别不大,自定义类型前置式效率不低于后置式),应该优先使用前置式而不是后置式。但在某些情况下,必须使用后置式,在《Effective STL》中的 “第9条:慎重选择删除元素的方法” 就有这么一个集合删除的例子。
集合删除根据集合类型不同,需要使用不同的方法:
对于删除特定元素,如果集合c是一个标准的连续内存容器(vector、deque、string) 删除特定元素最好的方法是使用erase-remove方法:
std::vector<int> c{1,2,3,5};
c.erase(std::remove(c.begin(),c.end(),3),c.end());要删除集合c中的元素3,可以使用erase-remove来完成。
如果c是list,则可以直接使用remove方法。
std::list<int> l{1,2,3,5};
l.remove(3);如果c是关联容器(set、multiset、map、multimap),则删除元素的正确方法是调用erase。
std::set<int> s{1,2,3,5};
s.erase(3);但是,如果要删除满足某个判别式的元素,则方法会有所不同,比如要删除集合中的奇数元素,奇数oddValue定义如下:
bool oddValue(int i)
{
return i%2==1;
}对于标准的连续内存容器(vector、deque、string),使用erase-remove-if即可,例如如果要删除集合中的奇数(奇数的定义为oddValue),则可以使用如下方法:
std::vector<int> c1{1,2,3,5};
c1.erase(std::remove_if(c1.begin(),c1.end(),oddValue),c1.end());对于list,可以直接使用remove_if:
std::list<int> l1{1,2,3,5};
l1.remove_if(oddValue);对于标准关联容器(set、multiset、map、multimap),删除满足特定条件的元素没有特别直接的函数可以调用,必须我们自己写循环来实现。比较容易写的代码如下,
std::set<int> s1{1,2,3,5};
for (auto i= s1.begin();i!=s1.end();++i)
{
if (oddValue(*i))
{
s1.erase(i);
}
}上述代码会导致不确定的行为,当元素从集合中删除时,指向该元素的所有迭代器将会失效。一旦s1.erase(i)返回,i就会变成无效值。后面在这个无效的i值上进行递增,可能会使得整个循环变得不确定。
为了修正上述问题,需要在调用erase之前,有一个元素指向集合中的下一个元素。这样做最简单的办法就是对迭代器执行后置式自增操作:
std::set<int> s1{1, 2, 3, 5};
for (auto i = s1.begin(); i != s1.end(); /*什么也不做*/)
{
if (oddValue(*i))
{
s1.erase(i++);
}
else
{
++i;
}
}后置式递增表达式i++返回的是i的旧值,而作为副作用,i被递增,这样我们把旧i(未递增的值)传递给erase方法,但在erase开始执行前我们也递增了i,这正是我们想要的,非常完美。
参考:
Is there a performance difference between i++ and ++i in C? - Stack Overflow
C# postfix and prefix increment/decrement overloading difference - Stack Overflow
www.cnblogs.com/instance/archive/2011/05/21/2052722.html