Dictionary是一种存储键值对的数据结构,可以根据key快速查找对应的value,它的内部实现原理其实很简单,在浅谈算法和数据结构: 十一 哈希表一文中有详细介绍,但原理和实际的工程实现可能有所不同,.NET中有.NET Framework和.NET Core的两个版本,大体相同,但细节上又有所区别。这里以.NET Core中的Dictionary源码为例,来说明Dictionary的实现细节。
基本原理
为了保证插入和查找的平均复杂度为 O(1),hash table 底层一般都是使用数组来实现。对于给定的 key,先进行 hash 操作,然后相对哈希表的长度取模,将 key 映射到指定的地方。
index = hash(key) % hash_table_size // index 就是 key 存储位置的索引
这里的哈希函数没有特定的公式,但有一个目的就是要让产生的哈希值足够分散,有时候需要分析key的特征然后用一些常用的方法来精心构造哈希函数。
- 有可能不同的key,经过hash函数计算后,会生成相同的哈希值
- 由于hash table的size是有限的,在对长度取余后,难免会导致不同的key,最终产生的index是一样的。
以上两个原因会产生哈希冲突。处理哈希冲突有很多种方法,目前各大语言包括C++,Java,以及本文提到的C#,无一例外都是通过使用拉链法(separate chaining)来解决哈希冲突的。
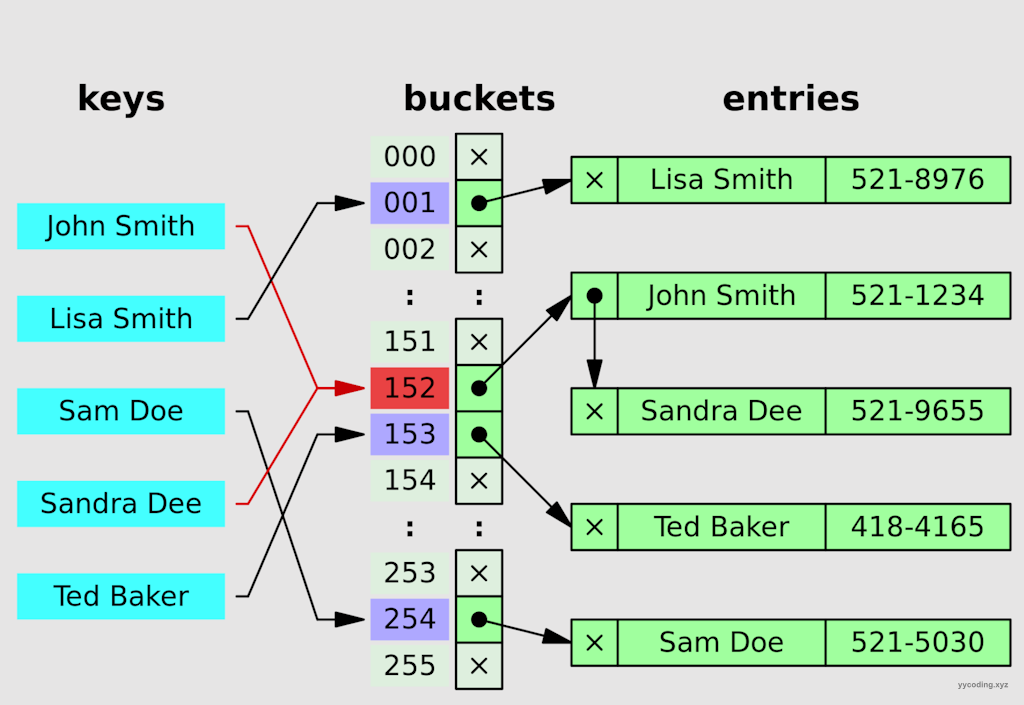
也就是说,如果多个不同的key映射到了相同的bucket上,那么这些key就用链表串起来。但如果这个链表过长,查找就会退化为线性的链表查找,有一些编程语言,会将这种过长的链表转化为红黑树。而有些变成语言,则会扩充bucket大小来重新计算index,从而试图减少单个bucket的最大链表长度。
以上可以看到,哈希表的原理非常简单,无非就是在每一个bucket上存储一个链表表头,这个链表保存了所有的经过哈希值取余后落到相同的bucket中的数据。但在实现中,还是有一些技巧和优化空间,这里以.NET Core来说明它的内部实现。
.NET Core中的实现
.NET Core中Dictionary的内部的实现需要一些基本的数据结构,最重要的是两个数组,一个是名为_bucket的int型数组。另一个是名为_entries的Entry类型的数组。这里为了提升性能,Entry类型使用了struct而没有使用class。使用struct可以减少内存占用,提升局部性以及避免GC,从而提升性能。struct结合返回ref类型,可以避免返回struct而产生额外拷贝开销,Entry的结构如下:
private struct Entry
{
public uint hashCode;
/// <summary>
/// 0-based index of next entry in chain: -1 means end of chain
/// also encodes whether this entry _itself_ is part of the free list by changing sign and subtracting 3,
/// so -2 means end of free list, -3 means index 0 but on free list, -4 means index 1 but on free list, etc.
/// </summary>
public int next;
public TKey key; // Key of entry
public TValue value; // Value of entry
}注意这里的next,它模拟单向链表指向下一个Entry。当这个Entry处于正常链表时,0表示第一个元素,-1表示链表的末尾。当Entry作为删除后的空闲链表时,需要先用-3-next,比如next为-2,则-3-(-2)=-1 表示空闲链表的末尾,next为-3,则-3-(-3)=0 表示空闲链表的index=0,表示第1个元素,-4表示空闲链表的index=1,表示第2个元素。
其它的字段及含义如下:
private int[]? _buckets; //Hash桶,key的哈希值对bucket长度取余后的值作为数组的index,对应的value值为存放value在entities元素中的索引index+1。
private Entry[]? _entries;//存储元素的数组
#if TARGET_64BIT
private ulong _fastModMultiplier; //在64位系统下,对取余优化
#endif
private int _count; //当前元素在entity中的索引位置,在freeCount=0时,也是下一个新元素待插入的位置
private int _freeList; //被删除Entry在entries中的下标index,这个位置是空闲的,如果freeCount=0,下一个新元素的待插入位置
private int _freeCount;//未删除的元素个数
private int _version;//版本号
private IEqualityComparer<TKey>? _comparer;//元素比较器
private const int StartOfFreeList = -3; //Entities在作为被删除对象的空闲列表时的特殊处理上面代码中,需要注意的是buckets、entries这两个数组,这是实现Dictionary的关键。另外还需要注意的是_buckets中存储的值是对应的元素在_entries中的下标+1。所以在获得某个_buckets[i]后要-1,才是对应entries中的链表的第一个元素。这里用图来说明整个流程。
Add操作
有三种方法可以往Dictionary里插入元素,它们在内部都是直接调用TryInsert方法,差别在于第2个参数InsertionBehavior的枚举值不同。
- Add方法,第2个参数为 InsertionBehavior.ThrowOnExisting, 表示如果字典中已经存在key对应的元素,则直接抛异常。
- TryAdd方法,第2个参数为 InsertionBehavior.None,表示如果字典中已经存在key对应的元素,不会抛出异常,什么都不做,直接返回false。
- 索引器,第2个参数为 InsertionBehavior.OverwriteExisting, 表示如果字典中已经存在key对应的元素,不会抛出异常,会直接覆盖之前的value。
所以如果需要向字典中插入元素,使用TryAdd和索引器的方式更好,如果允许插入的相同key的value覆盖可以覆盖之前插入的,那么直接使用索引器;如果只保留第一次key对应的value,后续相同的key不覆盖前面的value,则使用TryAdd;由于Add在key重复时会抛出异常,所以通常会搭配Contains使用,但这效率低下,TryAdd直接可以替代Contains+Add。
public TValue this[TKey key]
{
get
{
ref TValue value = ref FindValue(key);
if (!Unsafe.IsNullRef(ref value))
{
return value;
}
ThrowHelper.ThrowKeyNotFoundException(key);
return default;
}
set
{
bool modified = TryInsert(key, value, InsertionBehavior.OverwriteExisting);
Debug.Assert(modified);
}
}
public void Add(TKey key, TValue value)
{
bool modified = TryInsert(key, value, InsertionBehavior.ThrowOnExisting);
Debug.Assert(modified); // If there was an existing key and the Add failed, an exception will already have been thrown.
}
public bool TryAdd(TKey key, TValue value) => TryInsert(key, value, InsertionBehavior.None);核心的逻辑都在TryInsert方法里,方法的详情如下:
private bool TryInsert(TKey key, TValue value, InsertionBehavior behavior)
{
// NOTE: this method is mirrored in CollectionsMarshal.GetValueRefOrAddDefault below.
// If you make any changes here, make sure to keep that version in sync as well.
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (_buckets == null)
{
Initialize(0);
}
Debug.Assert(_buckets != null);
Entry[]? entries = _entries;
Debug.Assert(entries != null, "expected entries to be non-null");
IEqualityComparer<TKey>? comparer = _comparer;
Debug.Assert(comparer is not null || typeof(TKey).IsValueType);
uint hashCode = (uint)((typeof(TKey).IsValueType && comparer == null) ? key.GetHashCode() : comparer!.GetHashCode(key));
uint collisionCount = 0;
ref int bucket = ref GetBucket(hashCode);
int i = bucket - 1; // Value in _buckets is 1-based
if (typeof(TKey).IsValueType && // comparer can only be null for value types; enable JIT to eliminate entire if block for ref types
comparer == null)
{
// ValueType: Devirtualize with EqualityComparer<TKey>.Default intrinsic
while (true)
{
// Should be a while loop https://github.com/dotnet/runtime/issues/9422
// Test uint in if rather than loop condition to drop range check for following array access
if ((uint)i >= (uint)entries.Length)
{
break;
}
if (entries[i].hashCode == hashCode && EqualityComparer<TKey>.Default.Equals(entries[i].key, key))
{
if (behavior == InsertionBehavior.OverwriteExisting)
{
entries[i].value = value;
return true;
}
if (behavior == InsertionBehavior.ThrowOnExisting)
{
ThrowHelper.ThrowAddingDuplicateWithKeyArgumentException(key);
}
return false;
}
i = entries[i].next;
collisionCount++;
if (collisionCount > (uint)entries.Length)
{
// The chain of entries forms a loop; which means a concurrent update has happened.
// Break out of the loop and throw, rather than looping forever.
ThrowHelper.ThrowInvalidOperationException_ConcurrentOperationsNotSupported();
}
}
}
else
{
Debug.Assert(comparer is not null);
while (true)
{
// Should be a while loop https://github.com/dotnet/runtime/issues/9422
// Test uint in if rather than loop condition to drop range check for following array access
if ((uint)i >= (uint)entries.Length)
{
break;
}
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key))
{
if (behavior == InsertionBehavior.OverwriteExisting)
{
entries[i].value = value;
return true;
}
if (behavior == InsertionBehavior.ThrowOnExisting)
{
ThrowHelper.ThrowAddingDuplicateWithKeyArgumentException(key);
}
return false;
}
i = entries[i].next;
collisionCount++;
if (collisionCount > (uint)entries.Length)
{
// The chain of entries forms a loop; which means a concurrent update has happened.
// Break out of the loop and throw, rather than looping forever.
ThrowHelper.ThrowInvalidOperationException_ConcurrentOperationsNotSupported();
}
}
}
int index;
if (_freeCount > 0)
{
index = _freeList;
Debug.Assert((StartOfFreeList - entries[_freeList].next) >= -1, "shouldn't overflow because `next` cannot underflow");
_freeList = StartOfFreeList - entries[_freeList].next;
_freeCount--;
}
else
{
int count = _count;
if (count == entries.Length)
{
Resize();
bucket = ref GetBucket(hashCode);
}
index = count;
_count = count + 1;
entries = _entries;
}
ref Entry entry = ref entries![index];
entry.hashCode = hashCode;
entry.next = bucket - 1; // Value in _buckets is 1-based
entry.key = key;
entry.value = value;
bucket = index + 1; // Value in _buckets is 1-based
_version++;
// Value types never rehash
if (!typeof(TKey).IsValueType && collisionCount > HashHelpers.HashCollisionThreshold && comparer is NonRandomizedStringEqualityComparer)
{
// If we hit the collision threshold we'll need to switch to the comparer which is using randomized string hashing
// i.e. EqualityComparer<string>.Default.
Resize(entries.Length, true);
}
return true;
}其实逻辑不复杂,其中的一个while(true)循环是用来查找Dictionary中是否存在对应的key,以及统计碰撞次数。
Dictionary会随着元素的插入会自动扩容,这里为了演示各种操作,故先初始化大小为7,在内部会从预设的素数列表中,查找大于该数字的最小的素数。扩容在后面单独分析。现在初始化一个名为dic的Dictionary,为了简化哈希函数,选用int类型作为key,其哈希值为key本身,value为key对应的字符串表示。在初始化一个大小为7的字典后,内部结构如下:
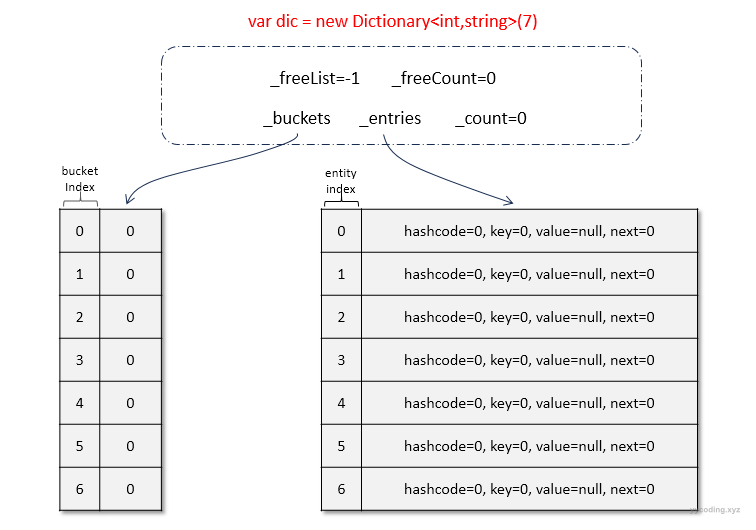
▲初始化大小为7的字典后,内部会初始化_buckets和_entries两个数组
紧接着执行插入操作。现在假设我们插入 ( 4, "4"),插入的步骤如下:
- 根据key的值,计算出它的hashCode。因为这里的key是int类型,所以哈希值就是key的值,即hashCode=4。
- 通过对hashCode取余运算,计算出该hashCode落在哪一个_buckets桶中。现在桶的长度(_buckets.Length)为7,那么就是4 % 7最后落在index为4的桶中,也就是_buckets[4],这里直接返回的是_buckets[4]存储的值的引用ref bucket,因为初始化完成之后,int的默认值是0,所以bucket的值为0。
- 查看bucket的值对应的_entries位置是否存在元素。现在bucket=0,这里_buckets存储的值时_entries的下标+1,所以_buckets[4]=0是指向_entries下标为-1的地方,即i=0-1=-1。在while循环中,首先将这个值转为无符号的int型,-1转换为无符号int型会溢出变为 4294967295 ,显然大于_entries的长度7,所以直接跳出循环。
- 由于空闲列表_freeCount为0,所以不会再空闲列表上分配。现在接下来将hashCode、key、value、next等信息存入entries[count]中,然后将count++指向下一个空闲位置。上图中第一个位置,index=count=0是空闲的,所以将元素放在entries[0]的位置,entries[0]的next设置为当前_buckets[4]对应的值即为i=-1(因为之后步骤5就要把当前的_bucket[4]指向下一个位置了)。
- 将_entries的下标entryIndex赋值给_buckets中对应下标的bucket。步骤4中是存放在了entries[0]的位置,所以_buckets[4]=0+1=1。注意上述代码中使用了ref 传递出来了bucket值,所以直接为bucket赋值1,就能达到_buckets[4]=1的效果。
添加完第一个元素后,整个结构如下:

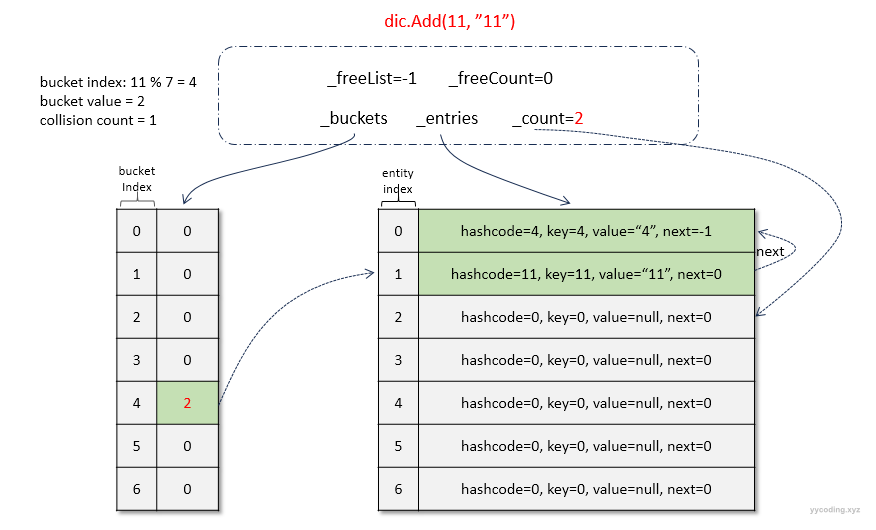
紧接着,又插入元素( 11, "11"),继续执行上述的步骤,可以看到11%7=4,恰好又放到了第4个bucket中,直接将新元素插入到_count指定的下一个空闲的位置index=1,然后将_count++;最后将(11,“11”)插入到_entries[1]中,它的next是当前_buckets[4]的值-1=1-1=0,最后将_buckets[4]的值赋值为index+1=2:插入完成之后,结构如下:
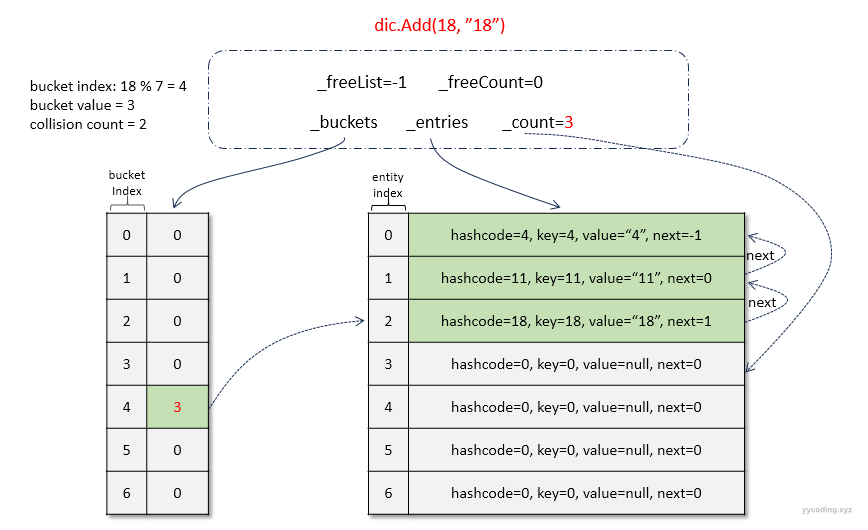
现在继续插入元素( 18, "18"),同样执行上述的步骤,可以看到18%7=4,又放到了第4个bucket中。步骤继续执行上述步骤即可,插入后整个结构如下:
继续插入( 19, "19")现在看到19%7=5,放到了第5个bucket中。buckets[5]=0,i=0-1=-1,表示没有元素,需要将新元素插入_count指向的空闲位置index=3,所以元素被插入到了_entries[3]的位置,_count++后等于4,_buckets[5]等于index+1=4。_buckets[5].next等于buckects[5]原先的值0-1=-1;插入之后内部元素状态如下:
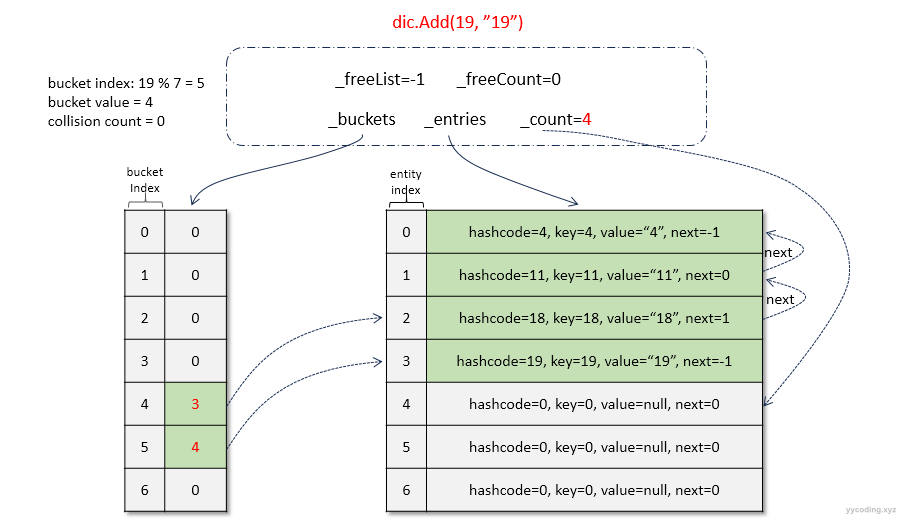
总结插入操作,可以看到,在_buckets的第4个槽中,一共存放了key为4、11、18这三个元素,_buckets[4]的值为3,对应的_entries的index为3-1=2,表示_buckets[4]对应的最近添加的一个数据存放在entries[3-1]的为位值,_entries[2]的下一个位置为next字段指向的1,即为_entries[1];_entries[1]的下一个位置为next字段指向的0即为_entries[0];_entries[0]的下一个位置为next字段指向的-1。-1即表示链表的末尾。在TryInsert的代码中,while循环里面是通过对next的值转型为uint无符号整形,然后跟_entries的长度来进行判断的,因为-1转换为无符号的整形会导致溢出为一个非常大的int值从而跳出查找的while循环。这一点可以说是非常的特别,我第一次看到有人专门使用负数转为无符号整形导致的溢出这个特征来实现逻辑处理,第一次看这个代码的时候觉得很奇怪,有一种“这一切的背后到底是道德的沦丧,还是人性的扭曲”的错觉,但是后来发现这个设计大胆且奇妙,因为由于溢出导致的欧空局的阿丽亚娜(Ariane)5型火箭爆炸教训实在是太深刻,这里竟然能够巧妙的加以运用。
Find操作
看完上面的插入操作,查找就非常简单了,因为上述的插入操作里面就包含了查找的部分逻辑,在插入的时候,首先需要判断对应key是否已经存在。查找操作的代码如下:
internal ref TValue FindValue(TKey key)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
ref Entry entry = ref Unsafe.NullRef<Entry>();
if (_buckets != null)
{
Debug.Assert(_entries != null, "expected entries to be != null");
IEqualityComparer<TKey>? comparer = _comparer;
if (typeof(TKey).IsValueType && // comparer can only be null for value types; enable JIT to eliminate entire if block for ref types
comparer == null)
{
uint hashCode = (uint)key.GetHashCode();
int i = GetBucket(hashCode);
Entry[]? entries = _entries;
uint collisionCount = 0;
// ValueType: Devirtualize with EqualityComparer<TKey>.Default intrinsic
i--; // Value in _buckets is 1-based; subtract 1 from i. We do it here so it fuses with the following conditional.
do
{
// Should be a while loop https://github.com/dotnet/runtime/issues/9422
// Test in if to drop range check for following array access
if ((uint)i >= (uint)entries.Length)
{
goto ReturnNotFound;
}
entry = ref entries[i];
if (entry.hashCode == hashCode && EqualityComparer<TKey>.Default.Equals(entry.key, key))
{
goto ReturnFound;
}
i = entry.next;
collisionCount++;
} while (collisionCount <= (uint)entries.Length);
// The chain of entries forms a loop; which means a concurrent update has happened.
// Break out of the loop and throw, rather than looping forever.
goto ConcurrentOperation;
}
else
{
Debug.Assert(comparer is not null);
uint hashCode = (uint)comparer.GetHashCode(key);
int i = GetBucket(hashCode);
Entry[]? entries = _entries;
uint collisionCount = 0;
i--; // Value in _buckets is 1-based; subtract 1 from i. We do it here so it fuses with the following conditional.
do
{
// Should be a while loop https://github.com/dotnet/runtime/issues/9422
// Test in if to drop range check for following array access
if ((uint)i >= (uint)entries.Length)
{
goto ReturnNotFound;
}
entry = ref entries[i];
if (entry.hashCode == hashCode && comparer.Equals(entry.key, key))
{
goto ReturnFound;
}
i = entry.next;
collisionCount++;
} while (collisionCount <= (uint)entries.Length);
// The chain of entries forms a loop; which means a concurrent update has happened.
// Break out of the loop and throw, rather than looping forever.
goto ConcurrentOperation;
}
}
goto ReturnNotFound;
ConcurrentOperation:
ThrowHelper.ThrowInvalidOperationException_ConcurrentOperationsNotSupported();
ReturnFound:
ref TValue value = ref entry.value;
Return:
return ref value;
ReturnNotFound:
value = ref Unsafe.NullRef<TValue>();
goto Return;
}这里面有1个专门针对ValueType值类型的分支,但逻辑跟引用类型是一样的。那就是首先根据key获取hashCode,然后用hashCode和_buckets的长度取余,得到的值减1,即为指向的该key对应的_entries中的第一个元素,然后比较该entry的hashCode和key,如果都相等则表示找到,否则继续查找当前_entries[i].next所指向的下一个元素,一直到_entries[i].next=-1,由于-1转为无符号int大于_entries.length从而跳出循环。
Remove操作
Remove的代码如下:
public bool Remove(TKey key)
{
// The overload Remove(TKey key, out TValue value) is a copy of this method with one additional
// statement to copy the value for entry being removed into the output parameter.
// Code has been intentionally duplicated for performance reasons.
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (_buckets != null)
{
Debug.Assert(_entries != null, "entries should be non-null");
uint collisionCount = 0;
IEqualityComparer<TKey>? comparer = _comparer;
Debug.Assert(typeof(TKey).IsValueType || comparer is not null);
uint hashCode = (uint)(typeof(TKey).IsValueType && comparer == null ? key.GetHashCode() : comparer!.GetHashCode(key));
ref int bucket = ref GetBucket(hashCode);
Entry[]? entries = _entries;
int last = -1;
int i = bucket - 1; // Value in buckets is 1-based
while (i >= 0)
{
ref Entry entry = ref entries[i];
if (entry.hashCode == hashCode &&
(typeof(TKey).IsValueType && comparer == null ? EqualityComparer<TKey>.Default.Equals(entry.key, key) : comparer!.Equals(entry.key, key)))
{
if (last < 0)
{
bucket = entry.next + 1; // Value in buckets is 1-based
}
else
{
entries[last].next = entry.next;
}
Debug.Assert((StartOfFreeList - _freeList) < 0, "shouldn't underflow because max hashtable length is MaxPrimeArrayLength = 0x7FEFFFFD(2146435069) _freelist underflow threshold 2147483646");
entry.next = StartOfFreeList - _freeList;
if (RuntimeHelpers.IsReferenceOrContainsReferences<TKey>())
{
entry.key = default!;
}
if (RuntimeHelpers.IsReferenceOrContainsReferences<TValue>())
{
entry.value = default!;
}
_freeList = i;
_freeCount++;
return true;
}
last = i;
i = entry.next;
collisionCount++;
if (collisionCount > (uint)entries.Length)
{
// The chain of entries forms a loop; which means a concurrent update has happened.
// Break out of the loop and throw, rather than looping forever.
ThrowHelper.ThrowInvalidOperationException_ConcurrentOperationsNotSupported();
}
}
}
return false;
}这里还是以图例说明,上面添加了key为4、11、18、19等4个元素之后。现在执行删除操作,先删除4,删除的步骤如下:
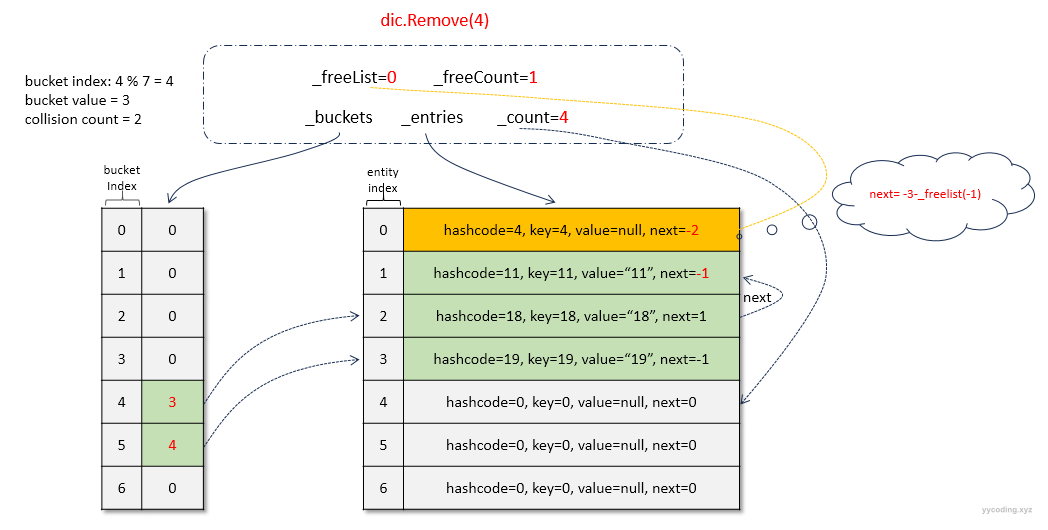
- 首先还是根据key计算hashcode,然后找到_buckets所在的槽对应的_entries对应的元素,在上述删除代码中就是bucket,i。
- 然后进行_entries[i]的hashCode和key值是否与待删除的相等相等,如果不相等继续next,这里last记录当前元素,i指向next
- 如果匹配,表示该_entries[i]就是要删除的元素。这里_entries[0]满足条件,此时last=1,所以只需要将当前待删除的元素_entries[0]的前一个元素,last执行的元素的next设置为当前待删除元素的下一个元素。即_entries[1].next=_entries[0].next,最后_entries[1].next=-1。
- 现在待删除的元素为_entries[0],需要将_entries[0]挂在到空闲列表上,将_entries[0].Value设置为默认值null,_entries[0].next设置为-3-_freeList=-3-(-1)=-2。
- 最后,更新_freeList=删除元素的index即0,表示_entries[0]元素为空闲列表中的最近一个删除的元素。然后_freeCount++自增为1,表示待删除列表中有1个元素。
删除第4个元素之后,各字段的状态如下:
继续删除元素 18,和上面删除4不同,4不是_buckets[4]=3指向的列表_entries[2]中的第一个元素_entries[2],而是这个元素的next的next为_entries[0],所以_buckets[4]对应的值不需要做修改。现在18对应的值,就是_buckets[4]=3对应的_entries[2]中的第一个元素_entries[2]。在代码中,对应的就是last=-1,在do循环中,第一个元素就满足相等要求,此时last<0,所以需要将_buckets[4]的值更改为待删除的元素_entries[2]的下一个元素_entries[2].Next的值1,即将_buckets[4]更新为1+1=2。同样,将待删除的元素_entries[2].Value设置为null,_entries[2].Next设置为-3-_freeList=-3。然后更新_freeList为当前待删除元素_entries[2]的index=2,_freeCount自增到2。
删除元素18之后,字段的状态为:
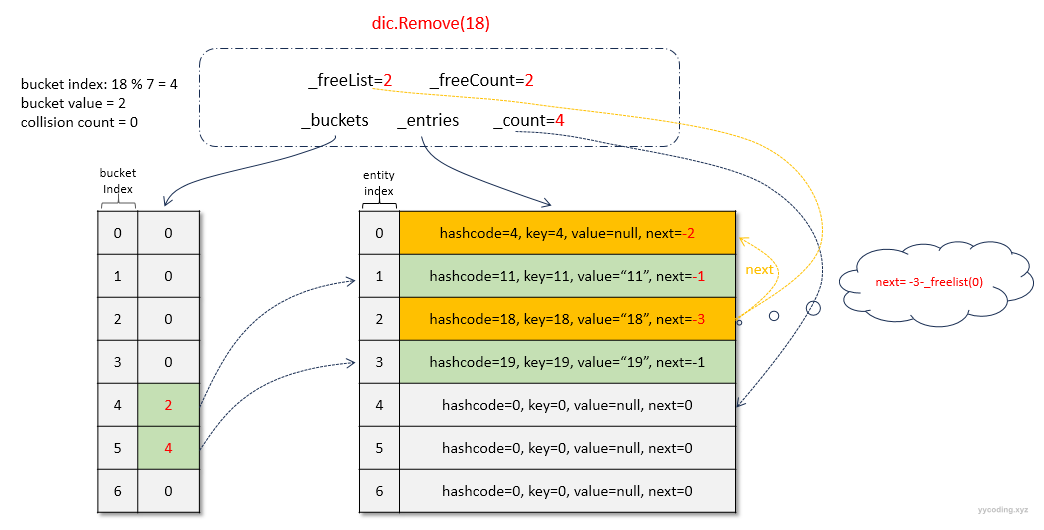
总结两次删除操作,可以看到,_freeList指向了最近一次删除元素在_entries中的索引,这个索引是以0开头的,并不是_buckets中指向的_entries中的以1开头。_freeCount记录了空闲列表中的删除元素的总个数。_freeList也指向了一个链表,其中的next的值是-3减去当前_freeList指向的元素index。比如上面的_entries[2].next=-3,用-3-(-3)=0,就表示它的下一个空闲元素就是_entries[0],_entries[0].next=-2,用-3-(-2)=-1,也表示是空闲列表的最后一个元素。
概况删除操作如下:
- 首先根据要要删除的key,找到_buckets[x]中指向的_entries列表中的第一个元素。
- 如果第一个元素就是要删除的元素_entries[y],那么修改_buckets[x]的值为待删除元素的next字段,以不使链表断裂。
- 如果第一个元素不是要删除的元素,则继续根据next往后查找,直至找到待删除的元素_entries[y],将_entries[y]的上一个元素的next,更新为_entries[y]的next,以防止链表断裂,因为这是一个单链表,所以要用一个变量last记录上一个链表,以方便执行删除链表中间元素的操作。
- 不管是步骤2还是步骤3,现在要修改删除元素_entries[y]的值,需要将其Value设置回默认值如果时引用类型就是null,然后将它的next设置为-3-_freeList,_freeList初始值为-1。
- 然后更新_freeList为最近删除元素_entries[y]的下标y,然后自增_freeCount++。
再次插入
之前的插入是在空闲列表为空的情况下的插入,在经过前面的两次删除之后,空闲列表已经有了两个元素,所以后面如果有新的元素插入,元素会插入到空闲列表指向的位置。这种删除元素后,不释放元素占据的空间,而是预留出来作为后续插入元素的位置,这样避免了重新分配内存,这种行为在C++中尤为常见,在C#的Queue的底层实现中环形缓冲区,包括.NET的托管堆中也存在这种行为,比如C#/.NET 对象分配的快进快出现象,GC居然私吞内存啦,这一切的一切都是为了提高内存的局部性,从而提高程序的效率。
在TryInsert的代码中可以看到:
int index;
if (_freeCount > 0)
{
index = _freeList;
Debug.Assert((StartOfFreeList - entries[_freeList].next) >= -1, "shouldn't overflow because `next` cannot underflow");
_freeList = StartOfFreeList - entries[_freeList].next;
_freeCount--;
}
else
{
int count = _count;
if (count == entries.Length)
{
Resize();
bucket = ref GetBucket(hashCode);
}
index = count;
_count = count + 1;
entries = _entries;
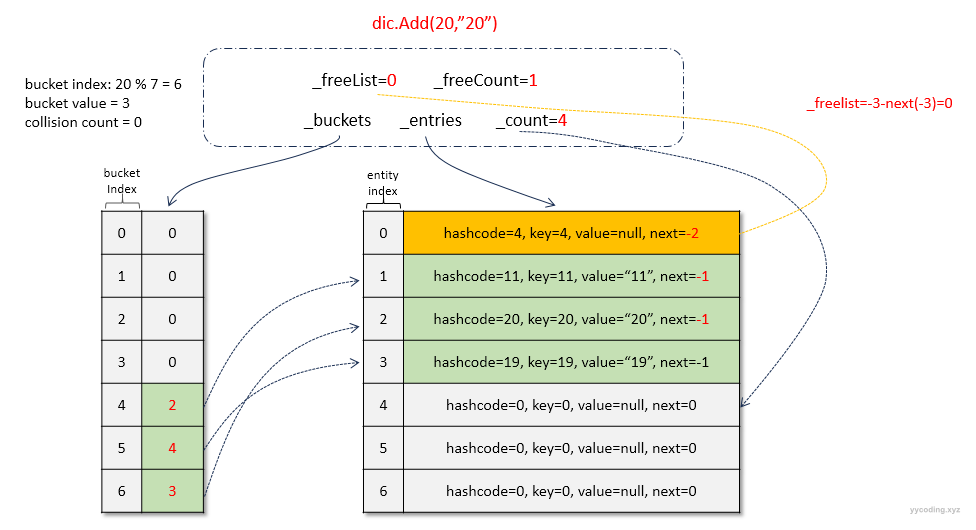
}当空闲列表不为空即_freeCount大于0时:
- 新插入的元素index就会放到_freeList指向的位置。
- 同时更新_freeList的值为_freeList指向的元素的next,即为-3-(_freelist).next
- 更新_freeCount--
- 将当前index的下一个元素设置为bucket当前指向的元素-1。
- 将_buckets指向的元素设置为当前index+1。
现在添加元素(20,"20")
扩容
当我们初始化给定大小时,内部会从预设的一组素数中,找出大于给定大小的最小素数。因为寻找素数是个比较耗时的操作,所以这里就预设了一些素数:
// Table of prime numbers to use as hash table sizes.
// A typical resize algorithm would pick the smallest prime number in this array
// that is larger than twice the previous capacity.
// Suppose our Hashtable currently has capacity x and enough elements are added
// such that a resize needs to occur. Resizing first computes 2x then finds the
// first prime in the table greater than 2x, i.e. if primes are ordered
// p_1, p_2, ..., p_i, ..., it finds p_n such that p_n-1 < 2x < p_n.
// Doubling is important for preserving the asymptotic complexity of the
// hashtable operations such as add. Having a prime guarantees that double
// hashing does not lead to infinite loops. IE, your hash function will be
// h1(key) + i*h2(key), 0 <= i < size. h2 and the size must be relatively prime.
// We prefer the low computation costs of higher prime numbers over the increased
// memory allocation of a fixed prime number i.e. when right sizing a HashSet.
internal static ReadOnlySpan<int> Primes => new int[]
{
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369
};这个预设的素数列表值,没有使用全部的素数,这里的素数大概是在前面元素的2倍附近,因为我们对容器进行扩容时通常也是2倍的扩容,所以这里是合理的选择。
在不同的语言中,比如C++的GNU中,他的hashset的预设素数如下,明显比.NET Core要稀疏很多。更密的素数能够减少内存的浪费。
template<typename _PrimeType> const _PrimeType
_Hashtable_prime_list<_PrimeType>::__stl_prime_list[_S_num_primes] =
{
5ul, 53ul, 97ul, 193ul, 389ul,
769ul, 1543ul, 3079ul, 6151ul, 12289ul,
24593ul, 49157ul, 98317ul, 196613ul, 393241ul,
786433ul, 1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul, 50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul, 1610612741ul, 3221225473ul, 4294967291ul
};C#中Dictionary的扩容有两种情况,第一种情况是插入的元素个数大于_entries的长度,第二种情况是某一个_buckets下所挂的链表过长超过了100。这个100是个常量:
public const uint HashCollisionThreshold = 100;现在先看第一种情况,假设新建一个Dictionary<int,string>不给初始值大小,第一次插入的时候,会默认分配第一个素数3的大小。接着分以下两种情况插入4条记录。
//case 1
var mydic = new MyDictionary<int, string>();
mydic.Add(1, "1");
mydic.Add(2, "2");
mydic.Add(3, "3");
mydic.Add(4, "4");//触发扩容
//case 2
var mydic = new MyDictionary<int, string>();
mydic.Add(1, "1");
mydic.Add(4, "4");
mydic.Add(7, "7");
mydic.Add(10, "10");//触发扩容两个case之后,内部结构如下:
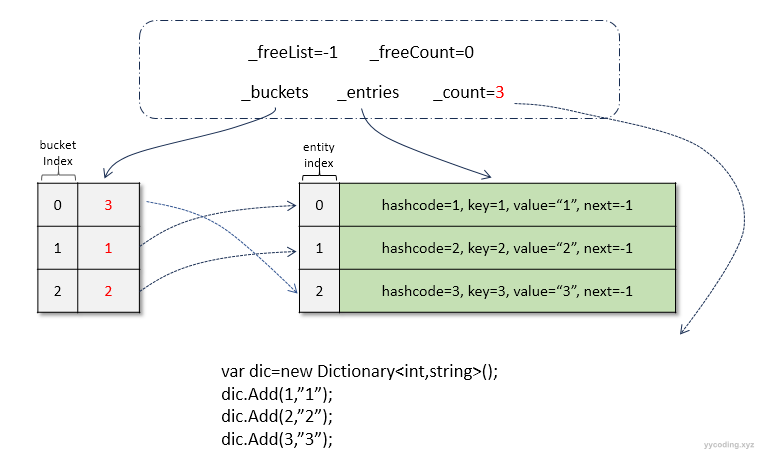
▲ case 1下变量布局
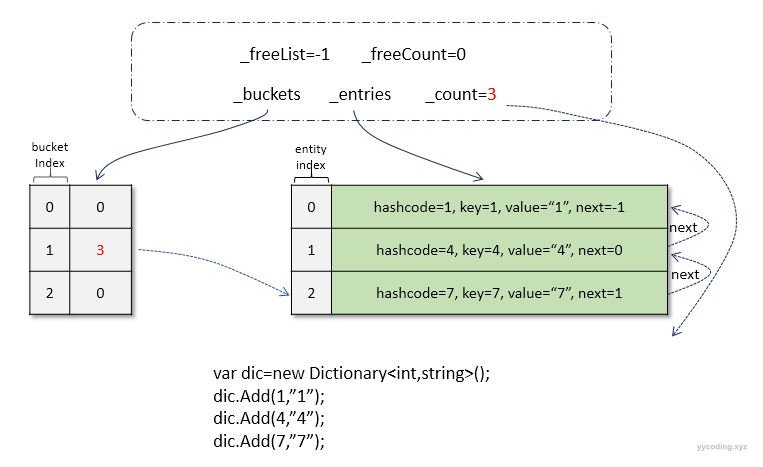
▲ case 2下变量布局
不管哪种情况,当大小为3的数组插入3个元素后count=3,当插入第4条数据时,发现 count==entries.Length,就会扩容,TryInsert中触发扩容的代码片段如下:
int count = _count;
if (count == entries.Length)
{
Resize();
bucket = ref GetBucket(hashCode);
}
index = count;
_count = count + 1;
entries = _entries;Resize的代码如下:
private void Resize() => Resize(HashHelpers.ExpandPrime(_count), false);
private void Resize(int newSize, bool forceNewHashCodes)
{
// Value types never rehash
Debug.Assert(!forceNewHashCodes || !typeof(TKey).IsValueType);
Debug.Assert(_entries != null, "_entries should be non-null");
Debug.Assert(newSize >= _entries.Length);
Entry[] entries = new Entry[newSize];
int count = _count;
Array.Copy(_entries, entries, count);
if (!typeof(TKey).IsValueType && forceNewHashCodes)
{
Debug.Assert(_comparer is NonRandomizedStringEqualityComparer);
IEqualityComparer<TKey> comparer = _comparer = (IEqualityComparer<TKey>)((NonRandomizedStringEqualityComparer)_comparer).GetRandomizedEqualityComparer();
for (int i = 0; i < count; i++)
{
if (entries[i].next >= -1)
{
entries[i].hashCode = (uint)comparer.GetHashCode(entries[i].key);
}
}
}
// Assign member variables after both arrays allocated to guard against corruption from OOM if second fails
_buckets = new int[newSize];
#if TARGET_64BIT
_fastModMultiplier = HashHelpers.GetFastModMultiplier((uint)newSize);
#endif
for (int i = 0; i < count; i++)
{
if (entries[i].next >= -1)
{
ref int bucket = ref GetBucket(entries[i].hashCode);
entries[i].next = bucket - 1; // Value in _buckets is 1-based
bucket = i + 1;
}
}
_entries = entries;
}扩容方法会调用HashHelpers方法里的ExpandPrime方法,该方法会将传进来的newSize=count*2,然后继续调用GetPrime函数从预定义的素数列表中找到大于该newSize的最小素数。
internal static partial class HashHelpers
{
public const uint HashCollisionThreshold = 100;
// This is the maximum prime smaller than Array.MaxLength.
public const int MaxPrimeArrayLength = 0x7FFFFFC3;
public const int HashPrime = 101;
// Table of prime numbers to use as hash table sizes.
// A typical resize algorithm would pick the smallest prime number in this array
// that is larger than twice the previous capacity.
// Suppose our Hashtable currently has capacity x and enough elements are added
// such that a resize needs to occur. Resizing first computes 2x then finds the
// first prime in the table greater than 2x, i.e. if primes are ordered
// p_1, p_2, ..., p_i, ..., it finds p_n such that p_n-1 < 2x < p_n.
// Doubling is important for preserving the asymptotic complexity of the
// hashtable operations such as add. Having a prime guarantees that double
// hashing does not lead to infinite loops. IE, your hash function will be
// h1(key) + i*h2(key), 0 <= i < size. h2 and the size must be relatively prime.
// We prefer the low computation costs of higher prime numbers over the increased
// memory allocation of a fixed prime number i.e. when right sizing a HashSet.
internal static ReadOnlySpan<int> Primes => new int[]
{
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369
};
public static bool IsPrime(int candidate)
{
if ((candidate & 1) != 0)
{
int limit = (int)Math.Sqrt(candidate);
for (int divisor = 3; divisor <= limit; divisor += 2)
{
if ((candidate % divisor) == 0)
return false;
}
return true;
}
return candidate == 2;
}
public static int GetPrime(int min)
{
if (min < 0)
throw new ArgumentException(SR.Arg_HTCapacityOverflow);
foreach (int prime in Primes)
{
if (prime >= min)
return prime;
}
// Outside of our predefined table. Compute the hard way.
for (int i = (min | 1); i < int.MaxValue; i += 2)
{
if (IsPrime(i) && ((i - 1) % HashPrime != 0))
return i;
}
return min;
}
// Returns size of hashtable to grow to.
public static int ExpandPrime(int oldSize)
{
int newSize = 2 * oldSize;
// Allow the hashtables to grow to maximum possible size (~2G elements) before encountering capacity overflow.
// Note that this check works even when _items.Length overflowed thanks to the (uint) cast
if ((uint)newSize > MaxPrimeArrayLength && MaxPrimeArrayLength > oldSize)
{
Debug.Assert(MaxPrimeArrayLength == GetPrime(MaxPrimeArrayLength), "Invalid MaxPrimeArrayLength");
return MaxPrimeArrayLength;
}
return GetPrime(newSize);
}
}扩容方法里,分配新的entries和_buckets,然后将原先的_entries拷贝新分配的entries中。如果强制重新计算哈希值,则重新计算。
完成之后,遍历_entities中的元素,获取存储的hashCode,然后计算落入到哪个槽,然后更新_buckets[i]的存储数据。
for (int i = 0; i < count; i++)
{
if (entries[i].next >= -1)
{
ref int bucket = ref GetBucket(entries[i].hashCode);
entries[i].next = bucket - 1; // Value in _buckets is 1-based
bucket = i + 1;
}
}
_entries = entries;另外一种扩容的情况就是当Dictionary足够大的时候,单buckets下面挂了超过100个元素时,会保持当前的长度不变,但强制更新生成hashCode,代码如下。
// Value types never rehash
if (!typeof(TKey).IsValueType && collisionCount > HashHelpers.HashCollisionThreshold && comparer is NonRandomizedStringEqualityComparer)
{
// If we hit the collision threshold we'll need to switch to the comparer which is using randomized string hashing
// i.e. EqualityComparer<string>.Default.
Resize(entries.Length, true);
}其它
在Dictionary的源码实现中,还有一些其它的细节,比如针对64位的快速取余算法;针对String类型哈希碰撞攻击的随机哈希优化;针对value类型的特殊处理等等。这里就不一一展开了。
源码调试
有时候看源代码可能还不够直观,需要能够断点进去逐步调试就更好。
好像可以针对源代码进行调试,但可能会比较慢,这里有两种方法。
第一种,可以在本地新建一个.NET Core的控制台程序,并在调试模式,设置断点,可以查看非公共成员变量,虽然不是源码级别调试,但可以看到内部的各个变量和字段的值以及变化情况。
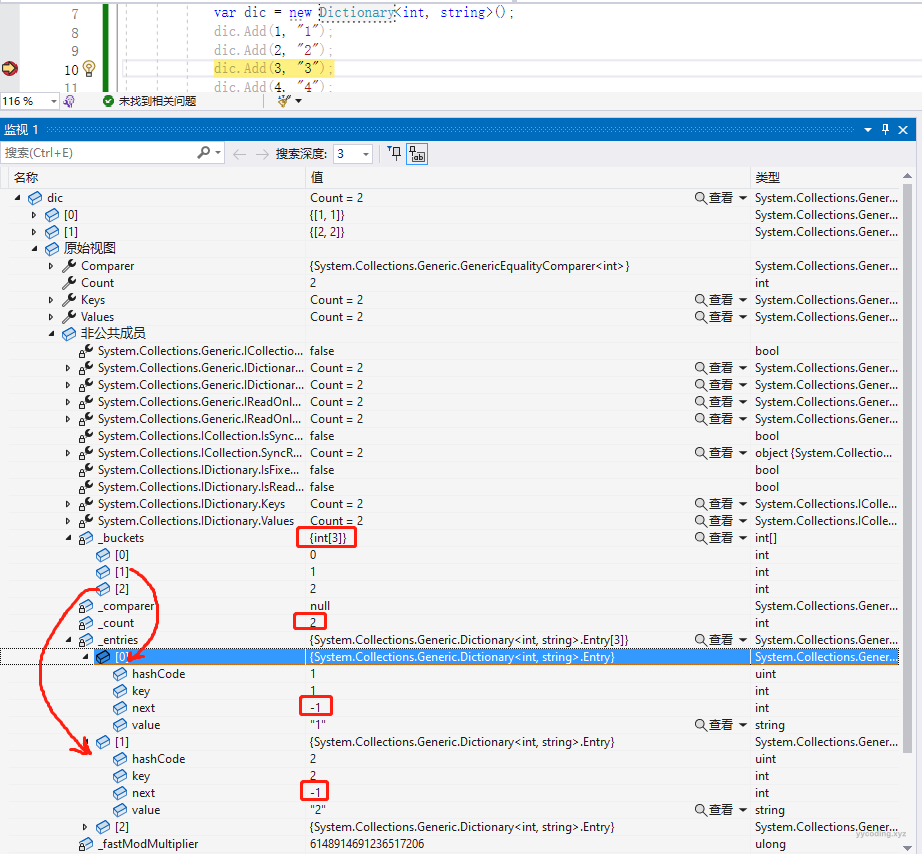
第二种就是将源代码中的Dictionary部分及相关主要的代码拷贝出来重命名,比如命名为MyDictionary来逐步调试运行,这样或许更加直观。所有的.NET源码中的基本数据结构的实现相对来说都比较独立,有些次要的逻辑代码可以注释掉来查看,这样能简化学习步骤,一下是我在看Dictionary源码时的做法。
总结
哈希表作为一种比较简单和基础的结构,在各大语言中有其标准的实现方式:那就是使用一个二维数组buckets来将哈希值分配到不同的桶中,对于冲突,则使用拉链法来解决,即使用单向链表,将分配到同一个桶中的值串起来,然后将_buckets中桶的值指向该链表的表头。
但不同的语言,针对其语言的特性,有自己独特的优化和实现方式,即使在同一个语言平台中,比如在.NET中,.NET 4.8和.NET Core的实现方式仍有差别,通过对.NET Core的分析可以发现有如下设计亮点:
- 存储Dictionary的Value的实体Entry在这里被设计为了值类型,而不是引用类型。一般而言,对于基本的数据类型或者纯字段或者小于16个字节的,设计为struct,而不是class能够明显提高内存局部性,并且能极大减少GC压力。特别地,相比class数组,struct数组的内存局部性有极大的优势。另外C# 7.0中引入的ref返回值类型,允许能直接返回对值类型的引用,从而避免了函数返回时对值类型的拷贝,这大大扩展了值类型的引用范围和简化了某些使用方法,比如在对key取哈希值并对_buckets的长度取余时,直接返回的ref bucket值,即直接返回取余后的槽的index的存储的值的引用,使得可以直接修改bucket的值,就能达到以前要通过_buckets[x]来修改其值的效果。
- 传统的拉链法解决冲突是通过在每个_buckets中分别创建一个链表来解决。在.NET Core中,则完全由一个跟_buckets同大小的_entries数组来充当所有_buckets的链表的实现。如前所述,entry是值类型,值类型的数组具有天然的内存局部性和高效率,使用数组而不是链表能极大的提升效率。
- 删除Dictionary某个key对应的元素,只是将_entries中对应的元素移到了空闲列表中,在下次插入时,优先把数据分配到空闲列表上。这样一定程度上能减少page交换,和新的内存注销和分配,这种技巧在C++编程语言中广泛存在,由于在非托管语言中,内存的注销和分配是一个相对来说比较好资源的操作,所以这种内存留用操作非常普遍,比如在GNU中容器分配器里,也是会将删除元素所占用的内存预留,在下一次分配时直接使用预留的内存而不是重新分配。
- 要用一个数组取代多个链表,并且在这个数组上既要作为普通的链表,也要作为空闲链表,这离不开对单向链表next值的特殊的精巧的设计。在插入操作时,元素插入到数组的count位置上,并将待插入的entry的next为当前_buckets[i]的值即count-1。在删除操作时,将entry的value重置为null,并将其next设置为一个特殊标记-3-(空闲列表表头_freeList),空闲列表表头默认为-1表示为空,这跟_buckets[i]的默认值为0,并且0-1=-1才表示对应的_entries中的索引一样,所以同样初始化后_buckets[i]中的值都为0,同样达到了类似空闲列表默认为-1表示列表为空的效果。
- 因为这个数组是模拟的单向链表,所以在删除元素时,必须保留前一个节点的位置last,删除某个节点时,需要将前一个节点的next指向当前待删除元素的next节点,这样单向链表就不会断,这也是常规操作了。
- 在判断链表是否到达尽头时,即next是否为-1时,对于普通储值的链表,直接将-1转换为uint,然后跟_entries的length做比较,这里利用了负数转为无符号整型会溢出成为非常大的整数的特性,比如-1转换为无符号会变成4294967295 ,所以一般情况下会大于_entries的长度,就直接跳出循环。那么有没有可能_entries的长度会扩展到大与4294967295,从而导致-1的转为uint后,仍然满足判断条件,这个在while循环里通过碰撞冲突的次数来限制了,所以不会出现死循环。
- 对于值类型的特殊优化处理,以及对于字符串的key为了避免哈希冲突攻击而进行的哈希值随机化处理。
参考资料
- 浅谈算法和数据结构: 十一 哈希表 - yycoding
- runtime/src/libraries/System.Private.CoreLib/src/System/Collections/Generic/Dictionary.cs at main · dotnet/runtime · GitHub
- dictionary.cs (microsoft.com)
- 【C#】浅析C# Dictionary实现原理 - 知乎 (zhihu.com)
- 带你看懂Dictionary的内部实现 - 独上高楼 - 博客园 (cnblogs.com)
- 浅析C# Dictionary实现原理 - InCerry - 博客园 (cnblogs.com)
- Dictionary implementation in C# - Dotnetos - courses & conferences about .NET
- Back to basics: Dictionary part 2, .NET implementation (markvincze.com)
- .NET CORE (C#) DICTIONARY INTERNALS - YouTube
- C#/.NET 对象分配的快进快出现象,GC居然私吞内存啦_哔哩哔哩_bilibili