
最近在使用的某个外部行情源API需要升级,于是在对接这一升级版本的行情处理代码中,重新审视了之前编写的代码,发现有一些可以优化的地方,这里记录一下。
通常,在构建高频交易(HFT)系统或极速行情接入组件(如行情网关)时,单写单读(SPSC)或多写单读(MPSC)的“生产者-消费者”队列模型是整个系统的数据流转枢纽。因为行情源的回调函数通常不应该处理过多的逻辑,否则会造成断线,所以消费者-生产者模型天然符合这一场景。当行情源产生数据时,将数据放到一个缓冲队列中,另外再开一个专门的线程去从队列里面取数据然后处理。这就涉及到了线程同步的问题,处理不当就会产生性能问题。
本文以XXXDataFeed 行情处理模块为例,分析同步机制的四次改进。这里剥离复杂的业务逻辑,给出每一代架构的结构实现,以演示何逐步提高系统性能。
ConcurrentQueue+AutoResetEvent方案
XXXDataFeed 最初的方案是使用ConcurrentQueue和AutoResetEvent来进行接收线程和处理线程的同步,核心代码如下:
public class XXXDataFeed_Stage1
{
private ConcurrentQueue<MarketData> mdQueue = new ConcurrentQueue<MarketData>();
private AutoResetEvent mdEvent = new AutoResetEvent(false);
private ManualResetEvent stopME;
private volatile bool running = true;
// 1. 生产者:底层回调
public void Quote_OnMarketData(MarketData md)
{
mdQueue.Enqueue(md);
mdEvent.Set(); // 高频引发内核态切换
}
// 2. 消费者:解析线程
private void ParseMD()
{
try
{
WaitHandle[] handles = new WaitHandle[] { stopME, mdEvent };
while (running)
{
int i = WaitHandle.WaitAny(handles);
if (i == 0)
{
return;
}
while (mdQueue.TryDequeue(out MarketData md))
{
//防止单个数据处理出现异常时导致整个循环结束,从而导致内存溢出
try
{
ProcessSingleMD(md);
}
catch (Exception e)
{
Logger.LogError(e);
}
}
}
}
catch (Exception e)
{
Logger.LogError(e);
}
}
// 3. 退出机制
public void Stop()
{
running = false;
mdEvent.Set(); // 唤醒沉睡的线程以退出
}
private void ProcessSingleMD(MarketData md) { /* 业务解析逻辑 */ }
}Quote_OnMarketData接收行情的回调方法和ParseMD处理行情的方法分属于不同的线程。这里采用 AutoResetEvent 进行线程同步。其缺陷在于用户态向内核态切换的性能损失。AutoResetEvent 封装的是底层的 Win32 内核事件对象。底层线程每压入一笔数据,都会触发一次 Set() 调用。即使此时消费者线程并未休眠,Set() 依然会强制 CPU 执行一次极其昂贵的上下文切换(从用户态陷入内核态)。在每秒数十万笔的冲击下,系统算力被大量消耗在状态切换而不是行情处理上。
另外在极端突发流量下,Set() 可能会引发信号丢失(连续 Set 两次只当作一次),迫使消费者必须用 while(TryDequeue) 榨干队列,稍微处理不慎就会漏唤醒。所以我们需要的是寻找更轻量级的数据同步方案。
BlockingCollection方案
为了规避昂贵的内核调用,系统进行了第一次重构,引入了 .NET 4.0 官方提供的 BlockingCollection。此方案利用了 BlockingCollection 内部的 SemaphoreSlim 和 SpinWait(自旋等待)机制。当队列为空时,消费者会先在用户态进行极短的自旋,完美规避了系统底层的内核调度。
代码如下:
public class XXXDataFeed_Stage2
{
// 包装了 ConcurrentQueue 的官方并发集合
private BlockingCollection<MarketData> blockingQueue = new BlockingCollection<MarketData>(new ConcurrentQueue<MarketData>());
private volatile bool running = true;
// 1. 生产者:底层回调
public void Quote_OnMarketData(MarketData md)
{
// 底层执行自旋锁优化,大幅减少内核切换
blockingQueue.Add(md);
}
// 2. 消费者:解析线程
public void ParseMD()
{
while (running)
{
if (mdQueue.TryTake(out MarketData md, 100))
{
do
{
//防止单个数据处理出现异常时导致整个循环结束,从而导致内存溢出
try
{
ProcessSingleMD(md);
}
catch (Exception e)
{
Logger.LogError(e);
}
}
while (running && mdQueue.TryTake(out md, 0));// timeout=0 表示不阻塞,尽可能掏空当前队列
}
}
}
// 3. 退出机制
public void Stop()
{
running = false;
blockingQueue.CompleteAdding(); // 优雅中断 GetConsumingEnumerable 循环
}
private void ProcessSingleMD(MarketData md) { /* 业务解析逻辑 */ }
}这个方案的好处是,使用了框架提供的适合消费者-生产者模型的数据结构。另外,ConcurrentQueue 是无界的,如果消费跟不上生产,会导致内存无限暴涨(Out Of Memory)。BlockingCollection 自带容量边界控制,可以在实例化时传入一个 boundedCapacity(比如 10000),当队列满时,生产者的写入动作会自动阻塞或返回 false,这可以防止内存溢出。
上述代码的逻辑为:
- 如果有数据,立即返回并取出。
- 如果没有数据,最多挂起 100 毫秒,这恰好充当了线程退出的轮询间隙,顺便判断一下 running。
- 取出一个数据后,用 TryTake(out md, 0) (0毫秒超时) 的内部循环把当前积压的队列全部瞬间清空,触发其它逻辑比如可以批量发送。
另外,这里的退出机制和之前的使用AutoResetEvent时和StopMe一起采用的WaitAny方案有所不同。现在采用的时最后一份数据处理完后再退出,使用的是CompleteAdding() + TryTake。而原先的WaitAny的方案是1毫秒都不耽搁的硬中断。要实现起来也简单,只需要增加一个CancellationTokenSource即可,代码如下:
public class XXXDataFeed_Stage2
{
// 包装了 ConcurrentQueue 的官方并发集合
private BlockingCollection<MarketData> blockingQueue = new BlockingCollection<MarketData>(new ConcurrentQueue<MarketData>());
private volatile bool running = true;
private CancellationTokenSource cts; // 新增
// 1. 生产者:底层回调
public XXXDataFeed_Stage2(string configName)
{
// ... 其他初始化 ...
cts = new CancellationTokenSource();
}
public void Quote_OnMarketData(MarketData md)
{
// 底层执行自旋锁优化,大幅减少内核切换
blockingQueue.Add(md);
}
// 2. 消费者:解析线程
public void ParseMD()
{
while (running && !cts.IsCancellationRequested)
{
// 【完美平替 WaitAny】:无限期阻塞等待,直到有数据,或者 cts.Cancel() 被调用
// 如果触发 Cancel,这里会瞬间抛出 OperationCanceledException
MarketData md = blockingQueue.Take(cts.Token);
do
{
//防止单个数据处理出现异常时导致整个循环结束,从而导致内存溢出
try
{
ProcessSingleMD(md);
}
catch (Exception e)
{
Logger.LogError(e);
}
}
while (running && !cts.IsCancellationRequested && blockingQueue.TryTake(out md, 0));// timeout=0 表示不阻塞,尽可能掏空当前队列
}
}
// 3. 退出机制
public void Stop()
{
running = false;
cts.Cancel(); // 发出取消信号,瞬间打断所有正在等待该 Token 的阻塞队列
}
private void ProcessSingleMD(MarketData md) { /* 业务解析逻辑 */ }
}然而因为它是通用组件,在源代码中可以看到,每次遍历都需要检查 CancellationToken、判断 IsAddingCompleted 标志等。面向接口的虚方法分发也阻碍了即时编译器(JIT)的内联优化。另外一个缺点是,与第一个方案相比,它没有类似AutoResetEvent的WaitHandle属性,从而不能够与现有的ManualResetEvent一起操作。所在ParseMD逻辑需要修动,代码没有原始版本的清晰。
BlockingCollection在内部是通过ConcurrentQueue+SemaphoreSlim来实现的,SemaphoreSlim是一个轻量级的同步原语。在消费者端,当队列为空需要等待时,它首先会在用户态进行短暂的自旋(SpinWait)。如果生产者在这几微秒内送来了数据,消费者就会被直接唤醒,完美避开了昂贵的内核态切换。在生产者端: Add() 操作由于没有使用操作系统的重量级事件,在常规状态下只涉及几个 Interlocked CAS 原子操作,其耗时几乎等同于普通的变量赋值。 核心代码简化之后如下:
// BlockingCollection 源码核心骨架 (简化版)
public class BlockingCollection<T>
{
private IProducerConsumerCollection<T> _collection; // 数据容器
private SemaphoreSlim _semaphore; // 信号量计数器
public BlockingCollection() {
_collection = new ConcurrentQueue<T>();
_semaphore = new SemaphoreSlim(0);
}
public void Add(T item) {
_collection.TryAdd(item); // 步骤1:无锁入队
_semaphore.Release(); // 步骤2:释放信号量
}
public T Take() {
_semaphore.Wait(); // 步骤1:等待信号量
_collection.TryTake(out T item); // 步骤2:无锁出队
return item;
}
}这里的实现和之前的ConcurrentQueue+AutoResetEvent类似,真正核心的地方在于SemaphoreSlim的Wait方法:
// SemaphoreSlim.Wait() 底层执行路径
public void Wait()
{
// 1. 纯用户态:尝试使用 Interlocked (CAS) 直接获取信号,如果成功,耗时仅几纳秒!
if (Interlocked.Decrement(ref m_currentCount) >= 0) {
return;
}
// 2. 自旋等待阶段 (The Magic Happens Here!)
SpinWait spinner = new SpinWait();
while (spinner.Count < SpinCountThreshold) {
spinner.SpinOnce(); // 在用户态空转,让出极少的时间片
// 在空转期间,如果生产者送来了数据,瞬间拿到并返回,避开了内核切换!
if (Interlocked.Decrement(ref m_currentCount) >= 0) {
return;
}
}
// 3. 终极妥协:如果自旋了很久还是没数据,说明真的闲下来了,
// 这时才调用 Monitor.Wait 陷入内核态休眠,交出 CPU。
FallBackToKernelWait();
}既然原理如此,那为什么我们不自己实现呢?于是就有了将最原本的AutoResetEvent改造为SemaphoreSlim的方案。
ConcurrentQueue+SemaphoreSlim方案
为了消除官方框架的冗余逻辑,开始SemaphoreSlim代替AutoResetEvent进行重写。重写后的核心代码如下:
public class XXXDataFeed_Stage3
{
private ConcurrentQueue<MarketData> mdQueue = new ConcurrentQueue<MarketData>();
private SemaphoreSlim mdSemaphore = new SemaphoreSlim(0);
private volatile bool running = true;
// 1. 生产者:底层回调
public void Quote_OnMarketData(MarketData md)
{
mdQueue.Enqueue(md);
mdSemaphore.Release(); // 用户态原子加法 (Interlocked.Add)
}
// 2. 消费者:解析线程
public void ParseMD()
{
List<MarketData> mds = new List<MarketData>(MaxBatchCount + 1);
while (running)
{
// 智能等待:10ms 延时保护下游吞吐量
if (mdSemaphore.Wait(10))
{
if (mdQueue.TryDequeue(out MarketData md))
{
ProcessSingleMD(md,mds);
// 只要有数据就获取
while (running && mdQueue.TryDequeue(out md))
{
// 每个release 需要对应一个wait
mdSemaphore.Wait(0);
ProcessSingleMD(md, mds);
}
FlushMD(mds);
}
}
}
FlushMD(mds);
}
// 3. 退出机制
public void Stop()
{
running = false;
mdSemaphore.Release(); // 强行唤醒阻塞的 Wait(10)
}
private void ProcessSingleMD(MarketData md, List<MarketData> mds) { /* 业务解析逻辑 */ }
private void FlushMD(List<MarketData> mds) { /* 业务解析处理 */ }
}这个方案的ParseMD代码,比之前更复杂了。因为需要达到两个目的:
- while循环里面,当没有数据到来时,不能死循环,需要停顿,所以需要一个带参数的Wait。
- SemaphoreSlim的每一个Release必须对应一个Wait,而且必须和ConcurrentQueue的Enqueue和TryDequeue一一对应。所以可以看到,在外层的一个Wait(10),必须要对应一个TryDequeue;同样内部的while循环里面的TryDequeue必须对应一个Wait(0)。
以上两个特性,使得代码看起来比较复杂,逻辑也不够清晰。
SemaphoreSlim的Release和Wait,在源代码内部,其实是通过Interlocked来操作一个整数来实现的。
目前的这个代码在本质上是对BlockingCollection的一次简化,虽然性能可能有提升。但是现在又有一个问题,采用ConcurrentQueue+SemaphoreSlim,这种计数型的信号量是否是我们真正需要的?
其实再回看方案一,我们只需要一个表示同步的“有”或“无”的状态即可,AutoResetEvent就是这样的,但是我们觉得它太过于笨重,于是首先想到了方案二的BlockingCollection,它替代了ConcurrentQueue+AutoResetEvent,由于BlockingCollection本身支持容量限制,所以它使用了一个带有计数性质的轻量级同步方案SemaphoreSlim。由于考虑到系统提供的数据结构的抽象成本,于是我们没有仔细思索的提出了方案三,即使用ConcurrentQueue+SemaphoreSlim这一简化版本的BlockingCollection方案。但是该方案的SemaphoremSlim计数和ConcurrentQueue的本身元素数量是需要保持同步的,所以导致代码教方案一的改动很大,且逻辑看起来冗余和不清晰,但是采用SemaphoreSlim确又不得不这样实现。
所以其实我们最需要的只是把AutoResetEvent这种代表有无状态的重心内核同步对象,换成一个轻量级的表示状态有无的同步对象,没有AutoResetEventSlim,但是有一个ManualResetEventSlim对象,这个可能就是我们想要的,这就是方案四。
ConcurrentQueue+ManualResetEventSlim方案
理论上由于ManualResetEventSlim并不需要像SemaphoreSlim那样计数,所以他的性能是要比后者高。使用ManualResetEventSlim替换AutoResetEvent是一个更好的选择,它的实现也更加简单,替换后的代码如下:
public class XXXDataFeed_Stage4
{
private ConcurrentQueue<MarketData> mdQueue = new ConcurrentQueue<MarketData>();
private ManualResetEventSlim mdEvent = new ManualResetEventSlim(false);
private volatile bool running = true;
// 1. 生产者:底层回调
public void Quote_OnMarketData(MarketData md)
{
mdQueue.Enqueue(md);
// 洪峰期间,除第一笔外,其余皆为 O(1) 短路读取,零消耗
mdEvent.Set();
}
// 2. 消费者:解析线程
public void ParseMD()
{
List<MarketData> mds = new List<MarketData>(200);
while (running)
{
// 无限期等待,午休期间 0% CPU 占用
mdEvent.Wait();
// 进入榨干循环前立刻重置,防止漏掉并发信号
mdEvent.Reset();
// 纯粹的无锁出队,内部没有任何同步包袱!
while (running && mdQueue.TryDequeue(out MarketData md))
{
ProcessSingleMD(md, mds);
}
// 排空即刷新 (Flush-on-Drain):杜绝任何内存逗留,消灭尾部延迟
FlushMD(mds);
}
}
// 3. 退出机制 (Graceful Exit)
public void Stop()
{
running = false;
// 人为发送最后一次唤醒信号,瞬间穿透 mdEvent.Wait() 并安全退出循环
mdEvent.Set();
}
private void ProcessSingleMD(MarketData md, List<MarketData> mds) { /* Flush逻辑*/}
private void FlushMD(List<MarketData> mds) { /* Flush逻辑*/}
}可以看到代码更加简洁,在ParseMD的While循环里面,没有联合StopMe来做WaitHandle等待,配合Stop方法里面的Set和内部While循环里面的running,也可以实现循环的优雅退出。在中午休市期间也能实现类似AutoResetEvent的内核级休眠,不消耗CPU资源。相比方案三:
- O(1) 的同步开销: ManualResetEventSlim.Set() 的底层源码,其第一行是 if (m_state) return;(短路评估)。在数据洪峰中,后续紧跟的数万笔数据调用 Set() 时,仅仅是一次纳秒级的普通布尔值读取,直接短路返回!消费者在内层循环出队时,也彻底甩掉了 Wait(0) 的计步器。同步开销随数据量增长的趋势从 O(N)变为了O(1)。这正是这种布尔型计数器想比信号型计数器的优点,它不需要记录数量,只需要判断有无。
- While里面的
Wait()让线程在午间休市时进入 0% CPU 占用的绝对深度休眠,依靠程序退出机制中的最后一次Set()即可实现零毫秒优雅停机。这与方案一一致,比方案三的没有数据到来时,隔一段时间尝试读取更优雅。
性能比较的基准测试
当然,理论的分析还需要数据的真实验证,这里在.NET Framework 4.5下,使用BenchmarkDotNet 0.10.3 编写了一个TesteCase,来测试这四种情况下的每100万次操作下的耗时比较:
// [MemoryDiagnoser] 用于追踪是否有额外的内存分配
// [SimpleJob] 指定测试运行策略,这里采用吞吐量测试
[MemoryDiagnoser]
[SimpleJob(RunStrategy.Throughput)]
public class QueueSynchronizationBenchmark
{
// 测试处理 100 万笔数据
private const int OperationsPerInvoke = 1_000_000;
/// <summary>
/// ConcurrentQueue + AutoResetEvent
/// 模拟XTP 消费者与生产者同步模式
/// </summary>
[Benchmark(Baseline = true)]
public void ConcurrentQueue_AutoResetEvent_Scheme()
{
var queue = new ConcurrentQueue<MockTickData>();
var autoEvent = new AutoResetEvent(false);
// 消费者线程
var consumer = Task.Factory.StartNew(() =>
{
int processed = 0;
while (processed < OperationsPerInvoke)
{
if (queue.TryDequeue(out var _))
{
processed++;
}
else
{
// 队列为空,陷入内核态等待
autoEvent.WaitOne();
}
}
}, TaskCreationOptions.LongRunning);
// 生产者线程 (主线程模拟)
for (int i = 0; i < OperationsPerInvoke; i++)
{
queue.Enqueue(new MockTickData { Price = i, Volume = i });
// 每次 Enqueue 后调用 Set()
autoEvent.Set();
}
consumer.Wait();
}
/// <summary>
/// BlockingCollection
/// </summary>
[Benchmark]
public void BlockingCollection_Scheme()
{
var bc = new BlockingCollection<MockTickData>(new ConcurrentQueue<MockTickData>());
// 消费者线程
var consumer = Task.Factory.StartNew(() =>
{
int processed = 0;
// GetConsumingEnumerable 是 BlockingCollection 提供的高效阻塞枚举器
foreach (var item in bc.GetConsumingEnumerable())
{
processed++;
if (processed == OperationsPerInvoke) break;
}
}, TaskCreationOptions.LongRunning);
// 生产者线程 (主线程模拟)
for (int i = 0; i < OperationsPerInvoke; i++)
{
// Add 内部使用 SemaphoreSlim,在极速入队时几乎是纯用户态的无锁开销
bc.Add(new MockTickData { Price = i, Volume = i });
}
bc.CompleteAdding();
consumer.Wait();
}
[Benchmark]
public void ConcurrentQueue_SemaphoreSlim_Scheme()
{
var queue = new ConcurrentQueue<MockTickData>();
using (var semaphore = new SemaphoreSlim(0))
{
var consumer = Task.Factory.StartNew(() =>
{
int processed = 0;
while (processed < OperationsPerInvoke)
{
// 阶段1:
if (semaphore.Wait(10))
{
if (queue.TryDequeue(out var item))
{
processed++;
// 阶段2
while (processed < OperationsPerInvoke && queue.TryDequeue(out item))
{
semaphore.Wait(0);
processed++;
}
}
}
}
}, TaskCreationOptions.LongRunning);
for (int i = 0; i < OperationsPerInvoke; i++)
{
queue.Enqueue(new MockTickData { Price = i, Volume = i });
semaphore.Release();
}
consumer.Wait();
}
}
[Benchmark]
public void ManualResetEventSlim_Scheme()
{
var queue = new ConcurrentQueue<MockTickData>();
using (var manualEvent = new ManualResetEventSlim(false))
{
var consumer = Task.Factory.StartNew(() =>
{
int processed = 0;
while (processed < OperationsPerInvoke)
{
if (manualEvent.Wait(10))
{
// 拿到信号后,立刻重置状态,防止漏掉并发信号
manualEvent.Reset();
while (processed < OperationsPerInvoke && queue.TryDequeue(out var item))
{
processed++;
}
}
}
}, TaskCreationOptions.LongRunning);
for (int i = 0; i < OperationsPerInvoke; i++)
{
queue.Enqueue(new MockTickData { Price = i, Volume = i });
manualEvent.Set(); // 生产者:如果已是 true,直接短路返回,零开销!
}
consumer.Wait();
}
}
}internal class Program
{
static void Main(string[] args)
{
// 警告:必须在 Release 模式下,按 Ctrl + F5(不带调试器)运行!
var summary = BenchmarkRunner.Run<QueueSynchronizationBenchmark>();
Console.ReadLine();
}
}使用x64在Release环境下编译运行,最后的结果如下:
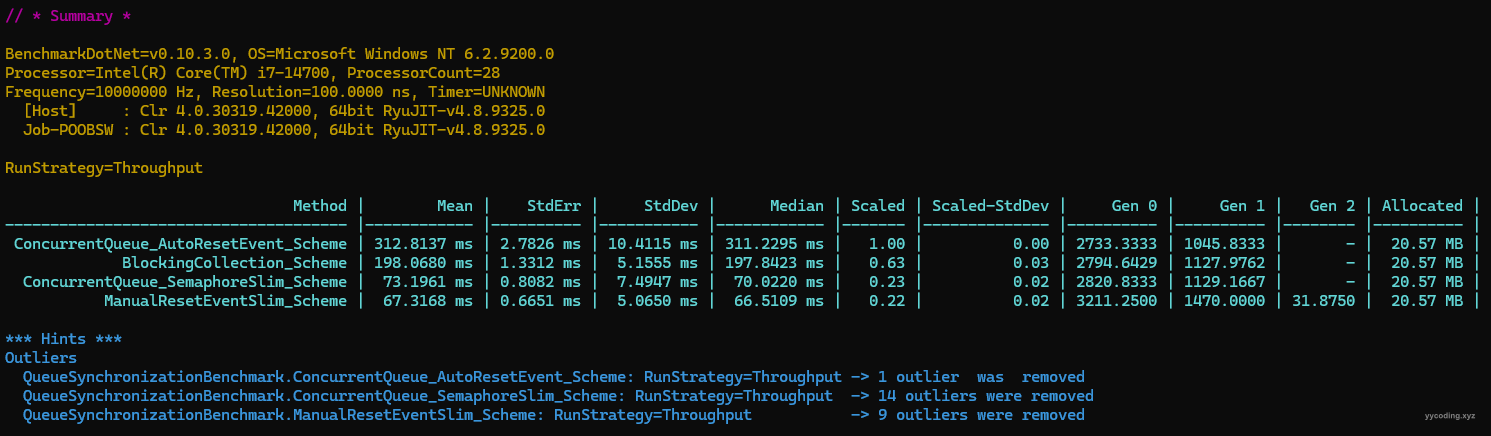
可以看到,后三种采用轻量级信号同步方案的消费者生产者模型,要比采用重量级信号量的要快至少37%以上。
总结
回顾这四次同步方案的改进,其实是对行情处理中“生产者-消费者”模型逐步适配的过程。
在最初的实现中,传统的 AutoResetEvent 引入了较多的内核态切换开销。随后测试的 BlockingCollection 和 SemaphoreSlim 虽然通过用户态自旋降低了这部分损耗,但其自带的计数特性,对于我们这种仅需感知“有/无数据”状态的行情分发场景来说,依然带来了一些逻辑上的复杂度。
最终选用的 ConcurrentQueue 配合 ManualResetEventSlim 方案,算是找到了一个比较平衡的契合点:既利用了轻量级原语避免频繁的上下文切换,又剥离了冗余的计数维护成本,实现了简单的状态短路读取。
从最终的基准测试结果来看,剥离不必要的同步包袱后,系统的吞吐量确实得到了相应的提升。在处理类似的高并发数据流时,有时候不需要太过复杂的设计,选择最贴合当前业务场景的基础数据结构和同步原语,往往就能获得不错的收益。以上是这次在重构行情对接模块时的一些实践记录,供参考交流。