在.NET Core的源代码中,除了常用的Dictionary、ConcurrentDictionary之外,还有几种名称包含Dictionary的数据结构,它们是ListDictionary、OrderedDictionary、SortedDictionary、HybirdDictionary和StringDictionary。这些个杂牌Dictionary用得很少,不看源代码可能还不知道😂。表面上看,好像都是Dictionary,但研究发现其内部实现却大不相同。
上面的几个类,有几个是不支持泛型的,看起来像是泛型类Dictionary<K,V>这种通用的泛型结构没有出来之前的临时替代,比如StringDictionary,它是一种Key为string的特化Dicitonary,显然现在来看已经过时了。下面就逐一分析这几个名称中包含Dictionary的数据结构。
ListDictionary
在前面的一篇文章中介绍了Dictionary的内部实现,在Dictionary内部其实是维护了两个数组_buckets和_entries,和一些字段,诸如_count,_freelist,_freeCount等等。当初始化一个Dictionary时可以指定一个初始化容量,Dictionary内部会找到“不小于该值的最小质数”来作为它使用的实际容量,最小是3。假设我们要初始化一个Dictionary<int,int>的字典,往其中插入1个元素,那么它占用的空间至少为80个字节:
private int[]? _buckets; //3个长度的int数组,12字节
private Entry[]? _entries;//3个长度的Entry数组,每个Entry数组占用4+4+4+4=16个字节,共48个字节
#if TARGET_64BIT
private ulong _fastModMultiplier; //在64位系统下,对取余优化
#endif
private int _count; //4字节
private int _freeList; //4字节
private int _freeCount;//4字节
private int _version;//4字节
private IEqualityComparer<TKey>? _comparer;//元素比较器
private const int StartOfFreeList = -3; //4字节可见,如果元素的个数比较少,维持Dictionary内部各种字段和状态所需内存会远远大于保存元素实际所需要的内存,这样使用Dcitonray类就会显得过“重”。另一方面,如果元素很少,则使用线性查找的时间复杂度相比Dictionary的常量复杂度可能比较接近,或者说在这种情况下使用Dictionary带来的查找优势并不明显。所以在当元素比较少时,使用List<KeyValuePair<Key,Value>>在需要读写的时候进行线性查找,效率也不会差。而且比Dicitonary内存占用更少,从而能显著减少GC压力,从而提升效率。
在元素个数比较少的情况下,具体来说就是,当元素个数小于10个时,可以使用ListDictionary来代替Dictionary来提高效率。ListDicitonary在内部使用一个单向链表来存储键值对,为啥不是LinkList这种双向链表,因为多一个指向前面的指针就会多一点内存占用,在元素个数比较少的情况下,单向链表已经足够。
public class DictionaryNode
{
public object key = null!; // Do not rename (binary serialization)
public object? value; // Do not rename (binary serialization)
public DictionaryNode? next; // Do not rename (binary serialization)
}在内部维护了一个表示链表头的字段,并实现了IDictionary接口。
/// <devdoc>
/// <para>
/// This is a simple implementation of IDictionary using a singly linked list. This
/// will be smaller and faster than a Hashtable if the number of elements is 10 or less.
/// This should not be used if performance is important for large numbers of elements.
/// </para>
/// </devdoc>
public class ListDictionary : IDictionary
{
private DictionaryNode? head; // Do not rename (binary serialization)
private int version; // Do not rename (binary serialization)
private int count; // Do not rename (binary serialization)
private readonly IComparer? comparer; // Do not rename (binary serialization)
public ListDictionary()
{
}
public ListDictionary(IComparer? comparer)
{
this.comparer = comparer;
}
}唯一的遗憾是,该类型不是泛型,如果存储值类型可能会遇到装箱拆箱。此外引用类型在获取数据后还需要进行类型转换。
要实现一个泛型的ListDictionary也很简单,只需要将上述代码复制一下,修改即可。或者自己包装一下LinkedList<KeyValuePair<TKey,TValue>>,然后实现IDicitonary接口即可。
另外,也可以选择使用SortedList来实现ListDicitonary的功能,SortedList在内部实现跟List类似,它保存了两个数组,一个存储key,一个存储value,在插入元素的时候,对元素进行排序,但它有初始大小,能自动扩容,所以如果使用SortedList,在初始化时最好设置一下容器大小。由于是有序的,所以查找的时候可以使用二分查找法,理论上要比ListDictionary的线性查找更快,但SortedList内部还有其它一些诸如Keys,Values的私有字段,可能会增加内存占用,如果将这些改成只读属性,在获的时候动态获取就更好了。
在现实的场景中,如果核心或者被频繁调用的代码里,使用了Dictionary且其中的元素个数通常小于10个,那么在这种情况下,可以使用ListDicitonary取代Dictionary来减少内存占用和提高程序性能。在.NET程序的性能要领和优化建议一文中也提到这个问题:
在很多应用程序中,Dictionary用的很广,虽然字典非常方便和高效,但是经常会使用不当。在开发Visual Studio以及新的编译器中,使用性能分析工具发现,许多Dictionay只包含有1个元素或者干脆是空的。x86机器上,一个空的Dictionay结构内部会有10个字段在托管堆上会占据48个字节。当需要在做映射或者关联数据结构需要实现常量时间查找的时候字典非常有用。但是当只有几个元素,使用字典会浪费大量内存空间。相反,我们可以使用List<KeyValuePair<K,V>>结构来实现,对于少量元素来说,同样高效。如果仅仅使用字典来先加载数据,然后排序,然后读取数据,那么使用一个具有N(log n)的查找效率的有序数组,在速度上也会很快,当然这些都取决于的元素的个数。
HybridDictionary
从名字上来看,这是一个复合数据结构。从类的注释上可以看到,HybridDictionary首先会使用ListDictionary来保存元素。当元素过多时,转为使用哈希表。在字典中元素个数未知或者元素可能很少时,推荐使用HybirdDictionary。
/// <devdoc>
/// <para>
/// This data structure implements IDictionary first using a linked list
/// (ListDictionary) and then switching over to use Hashtable when large. This is recommended
/// for cases where the number of elements in a dictionary is unknown and might be small.
///
/// It also has a single boolean parameter to allow case-sensitivity that is not affected by
/// ambient culture and has been optimized for looking up case-insensitive symbols
/// </para>
/// </devdoc>
[Serializable]
[System.Runtime.CompilerServices.TypeForwardedFrom("System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089")]
public class HybridDictionary : IDictionary
{
// These numbers have been carefully tested to be optimal. Please don't change them
// without doing thorough performance testing.
private const int CutoverPoint = 9;
private const int InitialHashtableSize = 13;
private const int FixedSizeCutoverPoint = 6;
// Instance variables. This keeps the HybridDictionary very light-weight when empty
private ListDictionary? list; // Do not rename (binary serialization)
private Hashtable? hashtable; // Do not rename (binary serialization)
private readonly bool caseInsensitive; // Do not rename (binary serialization)
}具体来说,当初始化HybirdDictionary并且给定的初始容量initialSize大于等于 FixedSizeCutoverPoint (6) 时,直接在内部使用一个容量为initialSize大小的Hashtable。如果初始化的时候容量initialSize小于FixedSizeCutoverPoint(6),则在内部初始化一个ListDictionary。后续在往ListDictionary内部插入元素的时候,如果元素的已经达到了CutoverPoint-1个(8)时,那么会调用ChangeOver函数将ListDictionary转换为一个初始化大小InitialHashtableSize (13) 的Hashtable来存储,然后再插入元素。
private void ChangeOver()
{
Debug.Assert(list != null);
IDictionaryEnumerator en = list.GetEnumerator();
Hashtable newTable;
if (caseInsensitive)
{
newTable = new Hashtable(InitialHashtableSize, StringComparer.OrdinalIgnoreCase);
}
else
{
newTable = new Hashtable(InitialHashtableSize);
}
while (en.MoveNext())
{
newTable.Add(en.Key, en.Value);
}
// Keep the order of writing to hashtable and list.
// We assume we will see the change in hashtable if list is set to null in
// this method in another reader thread.
hashtable = newTable;
list = null;
}SortedDictionary
基本的Dicitonary由于内部是使用哈希表来存储数据,所以是不支持根据Key来进行排序的。如果要根据Key进行排序,可以使用SortedList,它在内部是使用两个数组来维护key和value的,能做到查询的时间复杂度为O(log n),但其插入和删除的时间复杂度为O(n),因为插入或者删除元素需要移动2个数组中的后续的所有元素。如果存储的元素很多,效率就很低下。
除了使用数组,还可以使用平衡查找二叉树即红黑树来保存数组,这样其查找,插入,删除元素的时间复杂度都可以做到O(log n),SortedDictionary就是这样一种数据结构,它在内部使用红黑树来保存数据。
public class SortedDictionary<TKey, TValue> : IDictionary<TKey, TValue>, IDictionary, IReadOnlyDictionary<TKey, TValue> where TKey : notnull
{
[NonSerialized]
private KeyCollection? _keys;
[NonSerialized]
private ValueCollection? _values;
private readonly TreeSet<KeyValuePair<TKey, TValue>> _set; // Do not rename (binary serialization)
public SortedDictionary() : this((IComparer<TKey>?)null)
{
}
public SortedDictionary(IComparer<TKey>? comparer)
{
_set = new TreeSet<KeyValuePair<TKey, TValue>>(new KeyValuePairComparer(comparer));
}
public TValue this[TKey key]
{
get
{
if (key == null)
{
throw new ArgumentNullException(nameof(key));
}
TreeSet<KeyValuePair<TKey, TValue>>.Node? node = _set.FindNode(new KeyValuePair<TKey, TValue>(key, default(TValue)!));
if (node == null)
{
throw new KeyNotFoundException(SR.Format(SR.Arg_KeyNotFoundWithKey, key.ToString()));
}
return node.Item.Value;
}
set
{
if (key == null)
{
throw new ArgumentNullException(nameof(key));
}
TreeSet<KeyValuePair<TKey, TValue>>.Node? node = _set.FindNode(new KeyValuePair<TKey, TValue>(key, default(TValue)!));
if (node == null)
{
_set.Add(new KeyValuePair<TKey, TValue>(key, value));
}
else
{
node.Item = new KeyValuePair<TKey, TValue>(node.Item.Key, value);
_set.UpdateVersion();
}
}
}
public int Count
{
get
{
return _set.Count;
}
}
public void Add(TKey key, TValue value)
{
ArgumentNullException.ThrowIfNull(key);
_set.Add(new KeyValuePair<TKey, TValue>(key, value));
}
public void Clear()
{
_set.Clear();
}
public bool ContainsKey(TKey key)
{
ArgumentNullException.ThrowIfNull(key);
return _set.Contains(new KeyValuePair<TKey, TValue>(key, default(TValue)!));
}
public bool ContainsValue(TValue value)
{
bool found = false;
if (value == null)
{
_set.InOrderTreeWalk(delegate (TreeSet<KeyValuePair<TKey, TValue>>.Node node)
{
if (node.Item.Value == null)
{
found = true;
return false; // stop the walk
}
return true;
});
}
else
{
EqualityComparer<TValue> valueComparer = EqualityComparer<TValue>.Default;
_set.InOrderTreeWalk(delegate (TreeSet<KeyValuePair<TKey, TValue>>.Node node)
{
if (valueComparer.Equals(node.Item.Value, value))
{
found = true;
return false; // stop the walk
}
return true;
});
}
return found;
}
public bool Remove(TKey key)
{
ArgumentNullException.ThrowIfNull(key);
return _set.Remove(new KeyValuePair<TKey, TValue>(key, default(TValue)!));
}
public bool TryGetValue(TKey key, [MaybeNullWhen(false)] out TValue value)
{
ArgumentNullException.ThrowIfNull(key);
TreeSet<KeyValuePair<TKey, TValue>>.Node? node = _set.FindNode(new KeyValuePair<TKey, TValue>(key, default(TValue)!));
if (node == null)
{
value = default;
return false;
}
value = node.Item.Value;
return true;
}
}SortedDictionary在内部实现上,完全将功能委托给了TreeSet对象,TreeSet对象是一个基本的继承自SortedSet的对象:
/// <summary>
/// This class is intended as a helper for backwards compatibility with existing SortedDictionaries.
/// TreeSet has been converted into SortedSet{T}, which will be exposed publicly. SortedDictionaries
/// have the problem where they have already been serialized to disk as having a backing class named
/// TreeSet. To ensure that we can read back anything that has already been written to disk, we need to
/// make sure that we have a class named TreeSet that does everything the way it used to.
///
/// The only thing that makes it different from SortedSet is that it throws on duplicates
/// </summary>
/// <typeparam name="T"></typeparam>
[Serializable]
[System.Runtime.CompilerServices.TypeForwardedFrom("System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089")]
public sealed class TreeSet<T> : SortedSet<T>
{
public TreeSet()
{ }
public TreeSet(IComparer<T>? comparer) : base(comparer) { }
internal TreeSet(TreeSet<T> set, IComparer<T>? comparer) : base(set, comparer) { }
[Obsolete(Obsoletions.LegacyFormatterImplMessage, DiagnosticId = Obsoletions.LegacyFormatterImplDiagId, UrlFormat = Obsoletions.SharedUrlFormat)]
private TreeSet(SerializationInfo siInfo, StreamingContext context) : base(siInfo, context) { }
internal override bool AddIfNotPresent(T item)
{
bool ret = base.AddIfNotPresent(item);
if (!ret)
{
throw new ArgumentException(SR.Format(SR.Argument_AddingDuplicate, item));
}
return ret;
}
}SortedSet则是一个标准的红黑树的实现:
// A binary search tree is a red-black tree if it satisfies the following red-black properties:
// 1. Every node is either red or black
// 2. Every leaf (nil node) is black
// 3. If a node is red, the both its children are black
// 4. Every simple path from a node to a descendant leaf contains the same number of black nodes
//
// The basic idea of a red-black tree is to represent 2-3-4 trees as standard BSTs but to add one extra bit of information
// per node to encode 3-nodes and 4-nodes.
// 4-nodes will be represented as: B
// R R
//
// 3 -node will be represented as: B or B
// R B B R
//
// For a detailed description of the algorithm, take a look at "Algorithms" by Robert Sedgewick.
internal enum NodeColor : byte
{
Black,
Red
}
internal delegate bool TreeWalkPredicate<T>(SortedSet<T>.Node node);
internal enum TreeRotation : byte
{
Left,
LeftRight,
Right,
RightLeft
}
[DebuggerTypeProxy(typeof(ICollectionDebugView<>))]
[DebuggerDisplay("Count = {Count}")]
[Serializable]
[System.Runtime.CompilerServices.TypeForwardedFrom("System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089")]
public partial class SortedSet<T> : ISet<T>, ICollection<T>, ICollection, IReadOnlyCollection<T>, IReadOnlySet<T>, ISerializable, IDeserializationCallback
{
}SortedDictionary的查找时间复杂度是O(log n),而普通的Dicitonary是O(1),但如果要使得key保持有序,则可以使用SortedDictionary更好。SortedList通过数组保存数据,它查找数据的时间复杂度也为O(log n),并且由于是数组保存,它的内存占用比SortedDcitionary更少,但在添加和删除操作的时间复杂度方面SortedDicitonary更优。所以要根据使用场景的插入和查询的频率,如果插入完成之后,只有查询操作,那么使用SortedList更好,如果查询、添加、删除的频率差不多,那么SortedDictionary更优。
OrderedDictionary
这个类的名称有极大的迷惑性,很可能让人认为它是跟SortedDictionary那样,存储时是按照key排好序的,实际上根本不是,我看改成叫IndexedDictionary可能更好。这个对象可以说用处不大,正与其注释里说的,可能在与数据库交互的时候有点儿用。
OrderedDictionary的唯一功能是除了可以通过key获取键值外,还可以通过索引号index来获取键值对。在内部它是通过一个名为_objectTable的Hashtable来保存键值对,同时还通过使用一个名为_objectArray的ArrayList的可变数组来保存同样的DictionaryEntry来实现的。
/// <devdoc>
/// <para>
/// OrderedDictionary offers IDictionary syntax with ordering. Objects
/// added or inserted in an IOrderedDictionary must have both a key and an index, and
/// can be retrieved by either.
/// OrderedDictionary is used by the ParameterCollection because MSAccess relies on ordering of
/// parameters, while almost all other DBs do not. DataKeyArray also uses it so
/// DataKeys can be retrieved by either their name or their index.
///
/// OrderedDictionary implements IDeserializationCallback because it needs to have the
/// contained ArrayList and Hashtable deserialized before it tries to get its count and objects.
/// </para>
/// </devdoc>
[Serializable]
[System.Runtime.CompilerServices.TypeForwardedFrom("System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089")]
public class OrderedDictionary : IOrderedDictionary, ISerializable, IDeserializationCallback
{
private ArrayList? _objectsArray;
private Hashtable? _objectsTable;
private int _initialCapacity;
private IEqualityComparer? _comparer;
private bool _readOnly;
private readonly SerializationInfo? _siInfo; //A temporary variable which we need during deserialization.
}其查找,插入代码如下:
/// <devdoc>
/// Inserts a new object at the given index with the given key.
/// </devdoc>
public void Insert(int index, object key, object? value)
{
if (_readOnly)
{
throw new NotSupportedException(SR.OrderedDictionary_ReadOnly);
}
ArgumentOutOfRangeException.ThrowIfGreaterThan(index, Count);
ArgumentOutOfRangeException.ThrowIfNegative(index);
Hashtable objectsTable = EnsureObjectsTable();
ArrayList objectsArray = EnsureObjectsArray();
objectsTable.Add(key, value);
objectsArray.Insert(index, new DictionaryEntry(key, value));
}
/// <devdoc>
/// Removes the entry at the given index.
/// </devdoc>
public void RemoveAt(int index)
{
if (_readOnly)
{
throw new NotSupportedException(SR.OrderedDictionary_ReadOnly);
}
ArgumentOutOfRangeException.ThrowIfGreaterThanOrEqual(index, Count);
ArgumentOutOfRangeException.ThrowIfNegative(index);
Hashtable objectsTable = EnsureObjectsTable();
ArrayList objectsArray = EnsureObjectsArray();
object key = ((DictionaryEntry)objectsArray[index]!).Key;
objectsArray.RemoveAt(index);
objectsTable.Remove(key);
}
/// <devdoc>
/// Removes the entry with the given key.
/// </devdoc>
public void Remove(object key)
{
if (_readOnly)
{
throw new NotSupportedException(SR.OrderedDictionary_ReadOnly);
}
ArgumentNullException.ThrowIfNull(key);
int index = IndexOfKey(key);
if (index < 0)
{
return;
}
Hashtable objectsTable = EnsureObjectsTable();
ArrayList objectsArray = EnsureObjectsArray();
objectsTable.Remove(key);
objectsArray.RemoveAt(index);
}在MSDN上有更多的例子,这里不赘述了。
总结
在平常代码中最常用的Dictionary在大部分情况下已经够用,但是在特定的场景下,使用其它的数据结构比Dictionary能够得到更少的内存占用和更好的性能。如果元素的个数少于10个,且处于关键的调用非常频繁的代码中,那么使用ListDictionary可以减少内存占用并且不会减少性能。
如果元素大小未知,且总体来说比较少,可以使用HybridDictionary,它的内部可以根据元素个数来决定是使用ListDictionary还是Hashtable来存储数据。
如果要保持key的有序遍历,则使用SortedDicitonary能满足要求,它在内部使用红黑树来实现,能在插入和查询之间达到良好的性能。如果要保持key有序,且插入删除少,查询多,那么也可以使用SortedList,它内存占用少。
最后一个就是OrderedDictionary,它提供了除了普通的Dicitonary功能之外,还提供了根据index来访问键值对的功能。下面这个表列出了上面这几种数据结构的各种效率以及使用场景,作为总结。
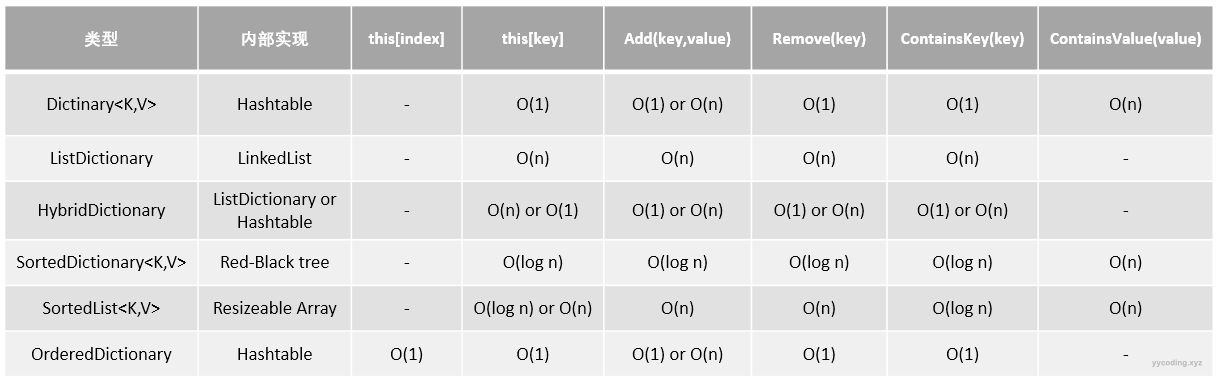
参考
- c# - Is there a generic alternative to the ListDictionary class? - Stack Overflow
- SortedDictionary<TKey,TValue> Class (System.Collections.Generic) | Microsoft Learn
- OrderedDictionary Class (System.Collections.Specialized) | Microsoft Learn
- c# - SortedList<>, SortedDictionary<> and Dictionary<> - Stack Overflow
- .NET程序的性能要领和优化建议 - yycoding-记录编程点滴
- 你的字典里有多少元素? - 老赵点滴 - 追求编程之美 (zhaojie.me)